
几乎所有现代操作系统都支持同时运行若干程序(至少在用户错觉是这样的)。这种错觉是由内核和处理器建立的,在很短的时间间隔内多任务不停切换。由于用户无法注意到短时间内的停滞,所以就造成了感官上的多任务并行。本文就一起来探究一下Linux是如果管理多任务的。
进程优先级
并非所有进程都具有同样的重要性,比如渲染屏幕的进程收到指令后要尽可能快的反馈到屏幕上,稍慢些用户就会感觉到卡顿,而用户分析计算数据的进程则不需要时刻反馈进度,只需要将结果返回即可。根据这个条件就可以粗略的将进程分为:实时进程和非实时进程。
- 硬实时进程,不能丝毫的耽误,例如火箭发射,机械控制。这些操作需要在规定时间内必须完成,否则会造成严重后果。主流Linux内核是不支持这类型进程的。
- 软实时进程,可以略微的耽误进度,例如写磁盘操作,需要尽快写到磁盘防止丢失,但机器负载较高时也可以暂停写入。
- 普通进程,不需要再明确的时间内完成的进程,这种进程就可根据优先级来分配调度。

调度时,unix系统中通常的做法是,将CPU时间进行分割,每个进程根据重要性分配一个时间片,然后进程依次使用CPU,时间到了就换下一个,这也就是抢占式多任务处理。
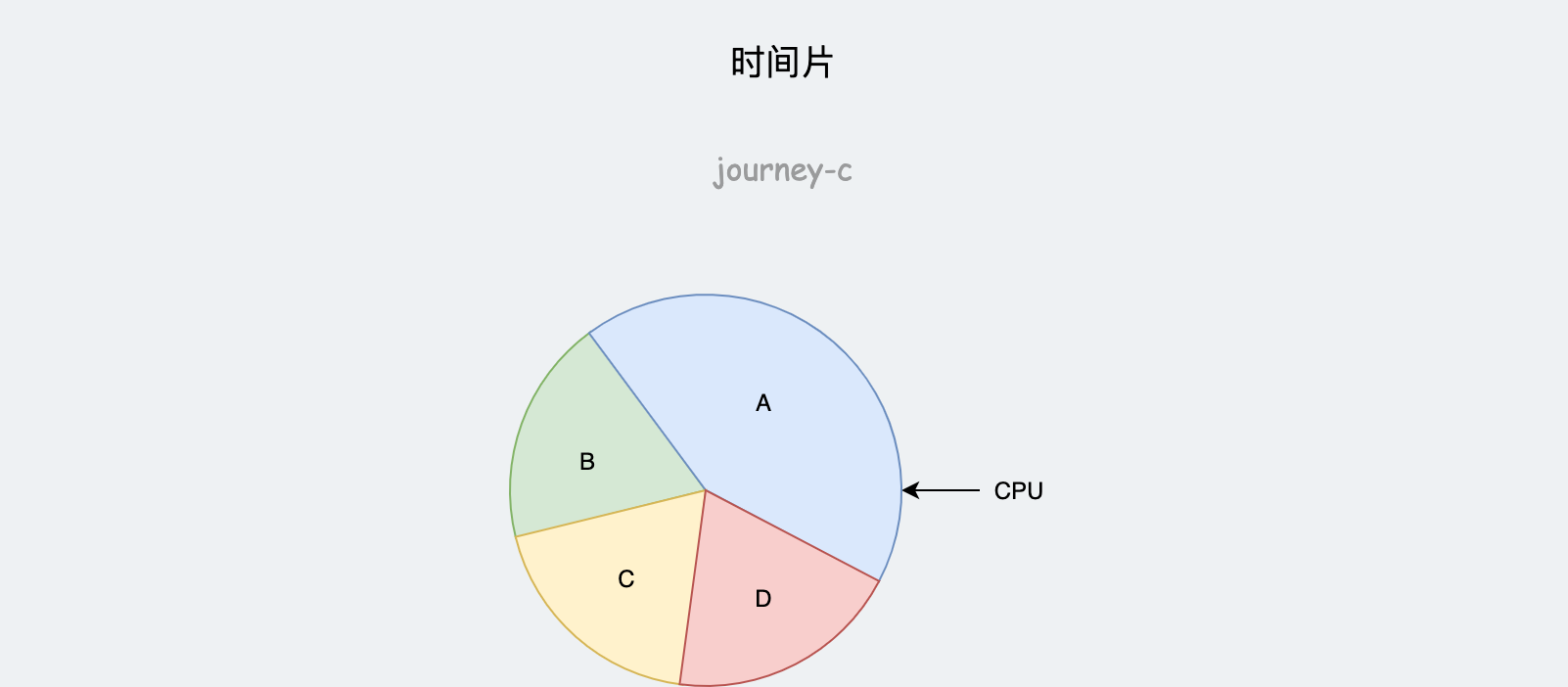
这种简单的模型没考虑到几个重要的问题:
- 进程某些时刻就是没有事情在做,占用CPU只会浪费。
- 时间片力度划分很难有一个标准,单位太小则频繁切换上下文产生无关任务的消耗,单位太大则分配不均匀。
Linux的内核开发者就此进行了非常热烈的讨论,Linux的调度算法需要满足进程分类的特点、满足不同负荷,即能在微型计算机上工作,又能在大型计算机上工作。这非常具有挑战性,Linux的调度算法至今进行过两次重大的重写:
- 2.5系列开发过程中,用所谓的O(1)调度器代替了前一个调度器,这个调度器的特点是可以在常数时间内完成调度工作,不依赖进程的数量。
- 2.6.23版本合并进来的完全公平调度器,将Linux真正变成可用的操作系统内核,该算法尽可能公平的调度每个进程,还可以特别关注某些进程,满足Linux进程分类的特点,也是沿用至今的调度器。这也是本章要讲的核心内容。
进程表示
既然要管理任务,就要有一个描述任务的数据结构,操作系统一般用进程来表示任务,Linux中将进程线程抽象为struct task_struct,struct task_struct中涉及了若干个子系统,十分的复杂,我们一点点来分析。

命名空间
在分析其他字段之前,先简单了解一下namespace的概念,因为后边讲的东西多多少少都会涉及这个特性。命名空间提供了虚拟化的一种轻量级形式,使得我们可以从不同的方面来查看运行系统的全局属性。该机制类似于Solaris中的zone或FreeBSD中的jail。
概念
传统的类UNIX系统中许多资源都是全局管理的,内核统一维护所有进程的ID,以及用户ID等,调用者调用uname命令看到的内核信息都是相同的。
全局管理可以有选择的允许或拒绝某些特权,0号进程几乎可以做任何事,但是其他用户的权限会被收敛,例如用户A不能杀死用户B的进程。虽然用户A不能杀死用户B的进程,但是能看到。Linux是多任务、多用户的的系统,没道理不让看其他用户的活动。
但是在有些情况下,这种特性并不是十分友好,例如云厂商对外提供计算服务,当然要给予他机器所有的权利,最直白的方式是给用户提供物理机,但是用户需要的计算能力不一样,并且采购也需要时间的,运营成品极高。使用KVM或VMWare提供的虚拟化环境是另一种解决问题的方案。但是这种方案的弊端明显,需要先虚出来硬件,然后在此基础上运行操作系统,虽然随着虚拟化的发展,性能损耗可以讲到1%以下。但是创建计算节点的耗时高还是给使用上带来了不便。

实现
资源隔离后所有资源不再是全局唯一,只有资源+资源所在命名空间的二元组全局唯一。

/* Namespaces: */
struct nsproxy *nsproxy;
struct task_struct中使用struct nsproxy来维护namespace的信息。
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
struct time_namespace *time_ns;
struct time_namespace *time_ns_for_children;
struct cgroup_namespace *cgroup_ns;
};
当前内核可以感知以下命名空间
- uts_ns 记录了内核名称、版本、体系结构等信息,通过
uname系统调用可以获取 - ipc_us 记录了进程间通信的信息
- mnt_ns 已经装载的文件系统的视图
- pid_ns_for_children 进程ID相关的信息
- net_ns 包含所有网络相关的命名空间参数
- time_ns和time_ns_for_children 维护了时间相关信息
- cgroup_ns 包含了计算资源分配相关的信息,例如CPU、内存、磁盘I/O等
- count是引用计数,各task通过指针指向相同的nsproxy,所以这里有一个引用计数
相同namespace进程通过指针指向同一个nsproxy结构,反之的指向不同nsproxy,这样就做到改变只影响本namespace。
相关操作
使用最频繁的操作就是获取当前进程所在的命名空间了。
- 如果没有给定数字类型pid或者struct task_struct结构体,就使用get_current()获取当前进程。
- 根据task_struct->thread_pid->level取出第几个struct upid
- struct upid中有对应的struct pid_namespace
进程ID
进程作为操作系统的一个核心概念,每个进程都有自己的ID:进程ID,也有自己的生命周期。

子进程有父进程,父进程也有父进程,这样就形成了以init进程为根的家族树。除了纵向的关系,还有横向的关系:进程组、会话组。
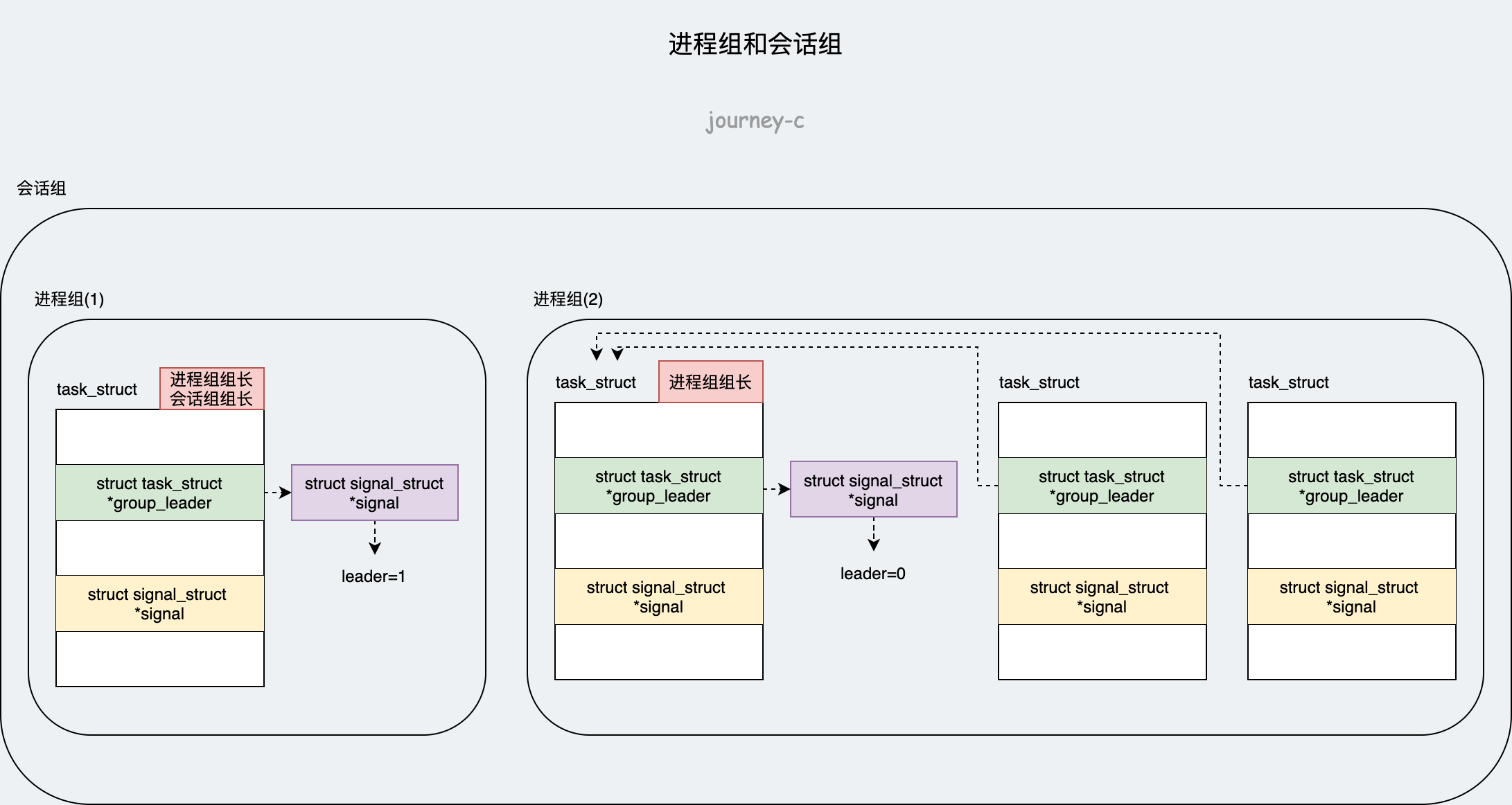
进程组和会话组的之间又形成了两级的关系:进程组是一组进程的集合,而会话组则是一组相关进程组的集合。
- 进程组组长,linux中直接在task_struct中用变量task_struct->group_leader指向进程组组长。
- 会话组组长,进程组组成会话组,所以会话内某个进程组组长就是会话组组长,每个进程组组长都有一个变量task_struct->group_leader->signal->leader来表示自己是不是会话组组长。
由上边的描述,进程就需要三个ID来标识不同身份:
- 进程ID(PID)进程的唯一标识。
- 进程组ID(PGID)一般为进程组组长的PID,创建新进程是默认会继承父进程PGID。
- 会话ID(SID)一般为会话组组长的PID,创建新进程是默认会继承父进程SID。
再细分的话,进程内部的工作单位还有线程,几个线程也可以合并为一个线程组。这样就又需要两个ID来标识身份:
- 线程ID(TID)Linux中当task_struct作为线程时、其TID的值为PID。
- 线程组ID(TGID)为线程组组长的TID,而线程组组长的TID就是整个进程的ID,所以Linux中又以TID是否为PID来判断线程是否为主线程。
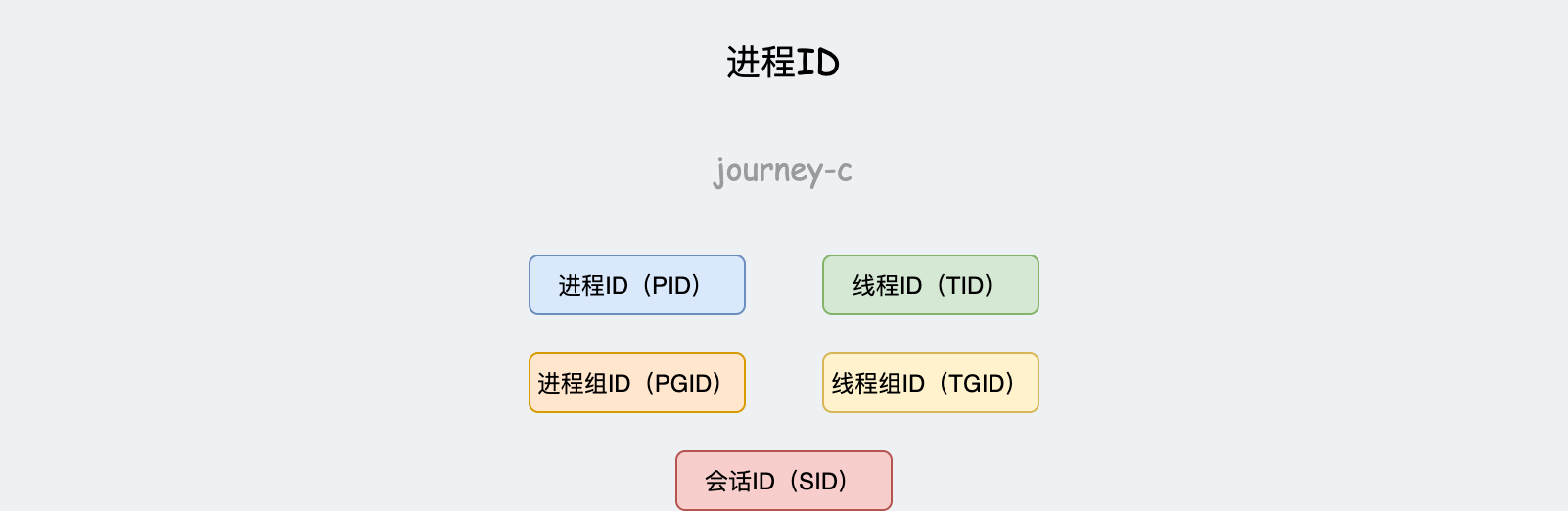
如果没有命名空间的特性的话,内核可以直接在struct task_struct使用五个数字类型的ID来表示上面定义的ID。但是命名空间的特性使得各种ID的维护变得更加的复杂。
PID的命名空间类似树形的层次结构,创建一个新的命名空间时,该空间内所有的PID都是对父命名空间以及上层的命名空间可见的。往上多一层就要多一个ID表示。
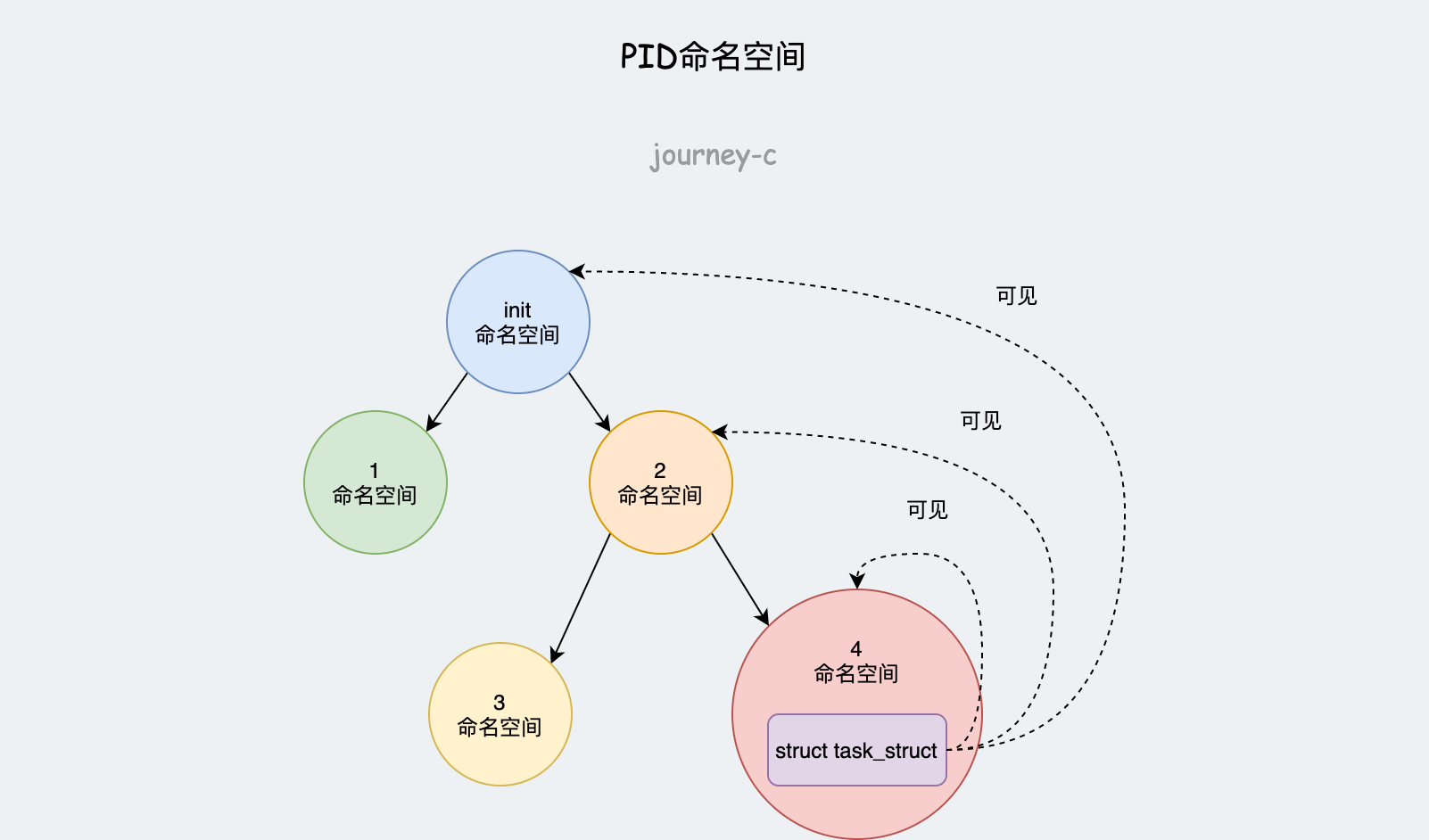
例如图中进程,对init命名空间、命名空间2、命名空间4可见,则PID就需要三个值来分别在三个命名空间表示唯一。
根据命名空间的分层,可以将PID分成两类:全局ID、局部ID
- 全局ID,是内核本身和初始命名空间(init进程所在namespace)的ID号。
- 局部ID,属于某个特定namespace,不同namespace间可以相同,但namespace内部不同。
全局ID
首先全局的pid和tgid直接保存在struct task_struct中。
struct task_struct {
...
pid_t pid;
pid_t tgid;
...
};
其余全局ID都可以用这两个ID来表示:
- 全局SID,为会话组组长的全局pid。
- 全局PGID,为进程组组长的全局pid。
- 全局TID,当task_struct为线程时,pid就是tid,则全局pid也就是全局tid
局部ID
除了全局ID这两个字段之外,内核还需要管理局部ID,因为增加了namespace的特性,所以这需要几个相互联系的数据结构,以及辅助函数。
数据结构
先来看一下pid的namespace表示方式。
struct pid_namespace {
...
struct task_struct *child_reaper;
...
unsigned int level;
struct pid_namespace *parent;
...
} __randomize_layout;
其中主要的变量:
- child_reaper 每个命名空间必须绑定一个进程,这个进程就相当于init进程,该进程也必须完成init进程的工作,例如对孤儿进程调用
wait4。 - parent 指向父命名空间。level表示当前命名空间的深度,初始为0,依次递增。level较低命名空间对较高命名空间可见。
局部pid的管理主要围绕两个数据结构:struct pid是内核对局部ID的表示,而struct upid则是PID在namespace内的可见信息。
struct upid {
int nr;
struct pid_namespace *ns;
};
struct pid
{
refcount_t count;
unsigned int level;
spinlock_t lock;
/* 使用该pid的进程列表 */
struct hlist_head tasks[PIDTYPE_MAX];
struct hlist_head inodes;
/* wait queue for pidfd notifications */
wait_queue_head_t wait_pidfd;
struct rcu_head rcu;
struct upid numbers[1];
};
首先是struct upid,变量nr表示id的数值,比如执行shell命令ps得到的PID就是取的这个值。ns指向对应的namespace。这样一个数据结构就能在增加namespace特性的情况下唯一的表示一个局部ID。
struct pid中count是一个引用计数,task是一个散列数组,包含了所有引用该struct pid的进程。因为同一个ID可能用于几个进程。比如进程组内进程组ID相同等。PIDTYPE_MAX表示ID的类型数。
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_TGID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX,
};
一个进程可能对多个namespace都可见,所以level表示namespace的深度,如图左下角。而numbers对应一个struct upid的数组,长度为level,表示在每个namespace的ID。注意该数组形式上只有一个数组项,如果一个进程只包含在全局命名空间中,那么确实如此。由于该数组位于结构的末尾,因此 只要分配更多的内存空间,即可向数组添加附加的项。
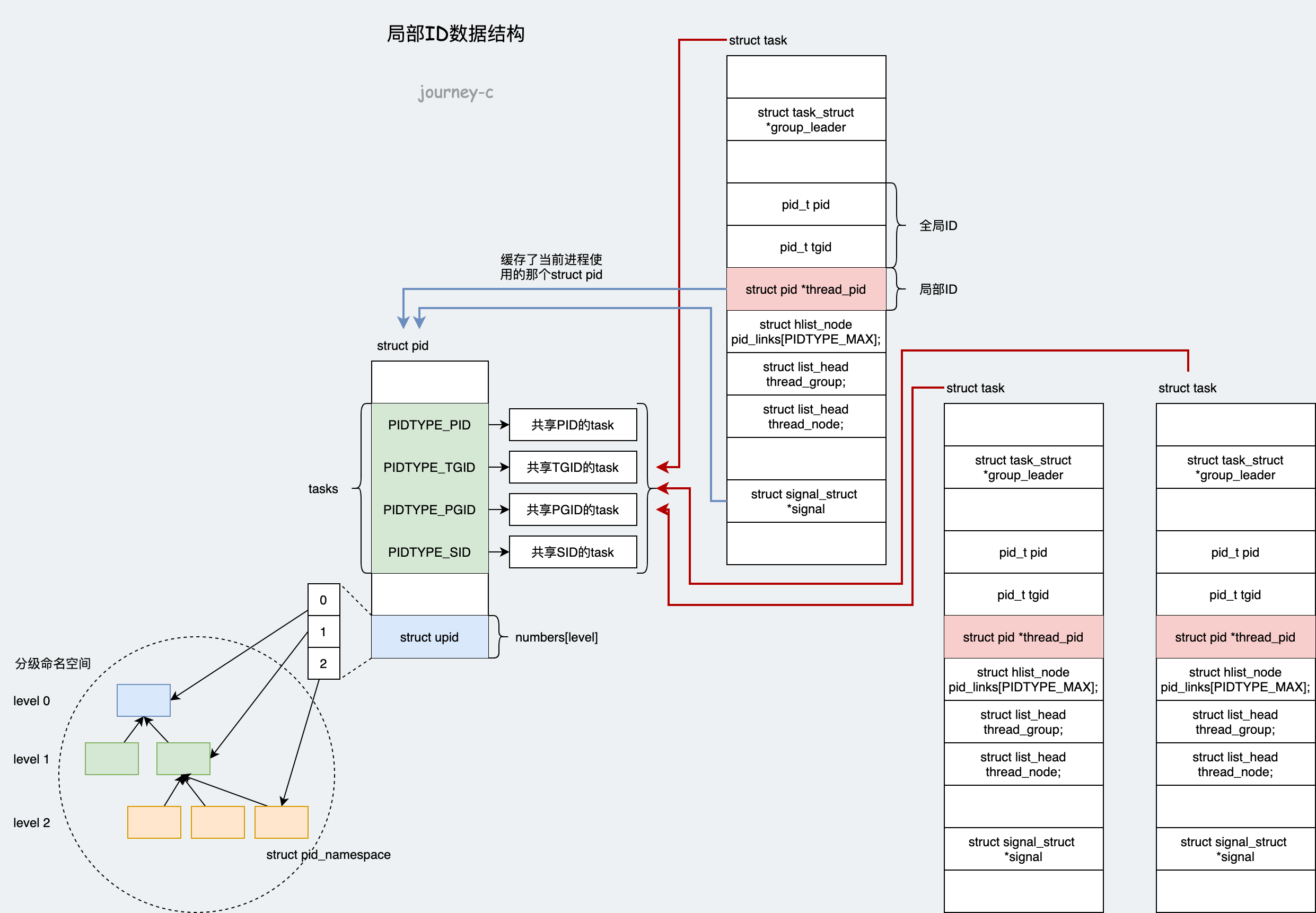
这三个数据结构的关系如上图:
- struct task_struct内部会有指向struct pid的指针,方便查找ID时找到数据结构。指向struct pid的指针也做了分类,像PID、TID这种一般不会进行组操作的ID就用struct pid *thread_pid指针缓存,查找PID时直接用这个指针。而PGID、TGID、SID这种需要组操作的ID就放在task_struct->signal->pids[PID_TYPE]里面,查找这三类ID时就直接从task_struct->signal->pids[PID_TYPE]查。
- 同时struct pid也会缓存引用他的struct task_struct,将引用他的struct task_struct都放在自身tasks变量中。
- struct pid中level变量会记录当前struct pid在第几层namespace,而pid->numbers记录了ID在各层ID数值。
函数
内核提供了若干函数辅助操作上面的三个数据结构,但本质离不开两个问题:
- 给定局部数字类型ID和namespace,如何找到对应的struct pid。
- 给出task_struct、ID类型和namespace,如何找到数字类型的ID。
在这两个问题之前,有个问题:如何找到进程所在的namespace?

首先如果没给定task_struct的话,可以调用current宏获取当前所在task_struct。
然后调用task_active_pid_ns获取namespace,大概流程就是,通过task_struct->thread_pid指针获的指向的struct pid,其变量记录了当前所在第几层namespace,然后从pid->numbers[level]变量中取出对应的struct upid,其变量记录了对应的namespace。
再回到前边两个问题:
[1]给定局部数字类型ID和namespace,如何找到对应的struct pid?
内核用基数树存储局部ID到struct pid的映射,实际就是存储了局部ID(数字类型)对应的struct pid的内存地址(数字)。
通过find_pid_ns找到局部ID对应的struct pid对象。
然后根据需要的ID的类型取出pid->tasks[ID_TYPE]散列表中第一个实例。
[2] 给出task_struct、ID类型和namespace,如何找到数字类型的ID?
- 通过task_struct和ID类型拿到struct pid:
- 然后根据struct pid和namespace找到对应数字类型ID,这里实际就是用namespace里的level去struct pid里取第几个struct upid,然后struct upid的成员变量nr就是所需要的数字类型id。
信号处理
/* Signal handlers: */
struct signal_struct *signal;
struct sighand_struct __rcu *sighand;
sigset_t blocked;
sigset_t real_blocked;
/* Restored if set_restore_sigmask() was used: */
sigset_t saved_sigmask;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
unsigned int sas_ss_flags;
这里定义了哪些信号被阻塞暂不处理(blocked),哪些信号尚等待处理(pending),哪些信号正在通过信号处理函数进行处理(sighand)。处理的结果可以是忽略,可以是结束进程等等。
信号处理函数默认使用用户态的函数栈,当然也可以开辟新的栈专门用于信号处理,这就是 sas_ss_xxx 这三个变量的作用。
进程状态

也就是进程的生命周期,Linux内核将上面的状态又进行了更细的划分。
/* -1 unrunnable, 0 runnable, >0 stopped: */
volatile long state;
int exit_state;
int exit_code;
int exit_signal;
/* Per task flags (PF_*), defined further below: */
unsigned int flags;
task_struct->state表示进程的状态,取值如下:
/* Used in tsk->state: */
#define TASK_RUNNING 0x0000
#define TASK_INTERRUPTIBLE 0x0001
#define TASK_UNINTERRUPTIBLE 0x0002
#define __TASK_STOPPED 0x0004
#define __TASK_TRACED 0x0008
- TASK_RUNNING 处于运行态进程(可被调度,不一定正在使用CPU)
- TASK_INTERRUPTIBLE 处于睡眠中的进程,可以被唤醒。例如正在做I/O操作,但这时候来了一个信号,还是可以唤醒这个进程的
- TASK_UNINTERRUPTIBLE 处于睡眠中并且不会被任何信号唤醒,只能等待操作完成,假如操作因为某些特殊原因完成不了,那么这个进程就无法被唤醒了,kill信号也无法唤醒,因为信号已经被忽略了。所以这是一个非常危险的状态,如果没有百分百的把握就不要将进程设置为这种状态。
- __TASK_STOPPED 暂停状态,收到某种信号暂停运行。SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOUT这些信号都能使进程陷入暂停。
- __TASK_TRACED 被追踪状态,例如使用gdb调试进程时,进程就处于__TASK_TRACED态。
使用时,state会是这几种状态中的一种,或者几种状态的组合(通过bit操作)
/* Used in tsk->exit_state: */
#define EXIT_DEAD 0x0010
#define EXIT_ZOMBIE 0x0020
EXIT_DEAD 和 EXIT_ZOMBIE都表示进程终止,有什么区别呢?
- EXIT_ZOMBIE 当进程结束时,最先进入EXIT_ZOMBIE态,这时只是任务执行完了,但是父进程还没执行wait()调用
- EXIT_DEAD 当父进程执行wait调用后,进程进入最终态EXIT_DEAD,就可以进行清理回收工作了
进程调度
以下是task_struct中调度相关的参数,这里就不细讲了,后边用到时在作说明。
// 标识:当前是否在运行队列
int on_rq;
// 优先级
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
// 调度器类
const struct sched_class *sched_class;
// 调度实体
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
// 调度策略
unsigned int policy;
// CPU可使用情况
unsigned int policy;
int nr_cpus_allowed;
const cpumask_t *cpus_ptr;
cpumask_t cpus_mask;
struct sched_info sched_info;
统计信息
生产中通常都会用各种工具查看进程的状态和一些指标,而这些值task_struct也是需要维护起来的。并且调度时也需要根据这些指标来挑选运行的进程。
// 用户态消耗CPU时间
u64 utime;
// 内核态消耗CPU时间
u64 stime;
// 用户态进程组消耗CPU时间
u64 gtime;
// 主动上下文切换次数
unsigned long nvcsw;
// 被动上下文切换次数
unsigned long nivcsw;
// 进程启动时间(不包含睡眠)
u64 start_time;
// 进程启动时间(包含睡眠)
u64 start_boottime;
进程关系
这里的进程关系是指纵向的父子关系。
struct task_struct __rcu *real_parent;
struct task_struct __rcu *parent;
struct list_head children;
struct list_head sibling;
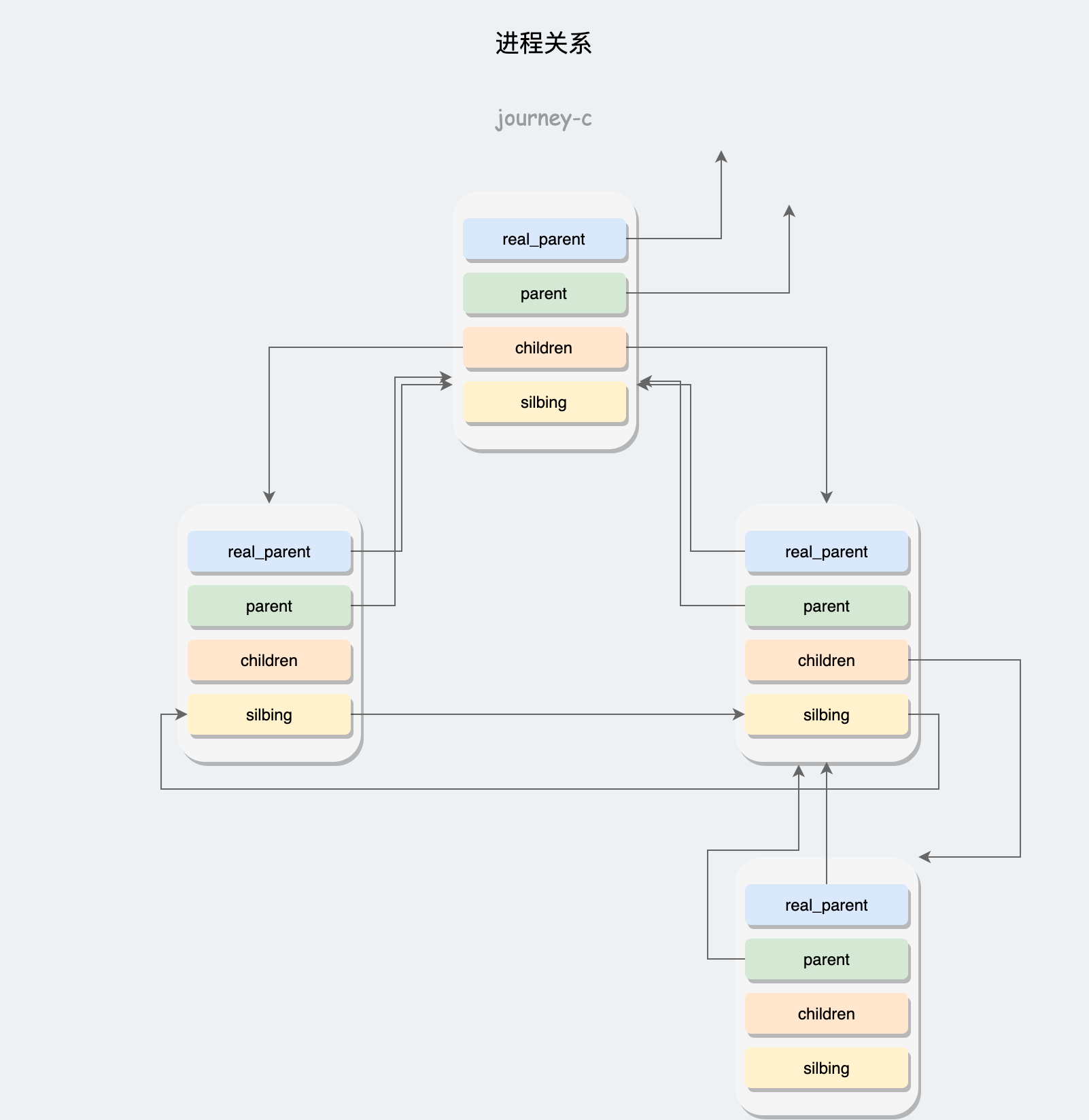
- real_parent 真实父进程,例如使用bash启动GDB调试一个进程,则real_parent为bash
- parent 父进程
- children 子进程列表
- sibling 兄弟进程列表
权限管理
Linux作为多任务、多用户的操作系统,自然要合理的分配管理每个用户的权限。task_struct中权限相关字段如下:
/* Process credentials: */
/* Tracer's credentials at attach: */
const struct cred __rcu *ptracer_cred;
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred;
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
- ptracer_cred trace进程对本进程的权限,例如GDB调试时,可以拥有哪些对被调试进程的权限。
- real_cred 其他进程对本进程的权限
- cred 本进程对其他进程的权限
接着看struct cred的定义:
struct cred {
...
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
...
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
...
} __randomize_layout;
前几个参数控制用户和组权限
- uid gid 启动该进程的进程的userid和groupid。实际使用时不会审核这个。
- euid egid 如注释,审核时使用的userid和groupid
- suid sgid 作为tmpid,当euid和egid切换时,临时保存
- fsuid fsgid 审核文件权限时使用
除了用户和组权限的管理,还有用户等级(能力)的管理,例如root和普通用户权利就不同。平常创建进程时要么用root权限要么用普通用户权限,但Linux实际具有非常详细的权限划分,叫做 capabilities机制。用位图表示是否有哪项权限。
#define CAP_CHOWN 0
#define CAP_DAC_OVERRIDE 1
#define CAP_DAC_READ_SEARCH 2
#define CAP_FOWNER 3
...
当有某项权限就可以做那项事情,没有则不可以,struct cred中:
- cap_permitted 表示进程被允许的权限,和cap_effective有差异。
- cap_inheritable 表示哪些权限可被继承,就是exec新进程时,哪些权限可以被加到新进程的cap_permitted中。
- cap_effective 表示进程能使用哪些权限,是cap_permitted的子集。
- cap_bset 使系统保留权限,如果cap_bset中没有某项权限,则所有进程都没有(包括root)。
- cap_ambient 是新加入的权限,为了解决继承问题,之前继承权限只会加入到新进程cap_permitted中,而cap_ambient会被同时加入到cap_permitted和cap_effective中。
内存管理
进程就是若干个子系统的集合,而内存模块的变量如下,这里就不多讲了,在《Linux内存管理》中讲得很详细了。
struct mm_struct *mm;
struct mm_struct *active_mm;
文件系统
文件子系统相关的字段如下。
/* Filesystem information: */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;
- fs 表示文件系统的类型
- files 表示本进程已打开的文件信息
栈空间
进程的执行实际就是一行行代码和函数的执行,函数的执行离不开栈来保存现场以及各种参数。除了单纯的调用,进程还要处理用户态和内核态的调用关系,例如系统调用的时候,函数怎么从用户栈跳到内核栈,然后再回来。
涉及变量如下:
/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/
struct thread_info thread_info;
void *stack;
先来了解一下什么是栈?栈的本质也是一段内存,下面是进程的虚拟内存的布局。
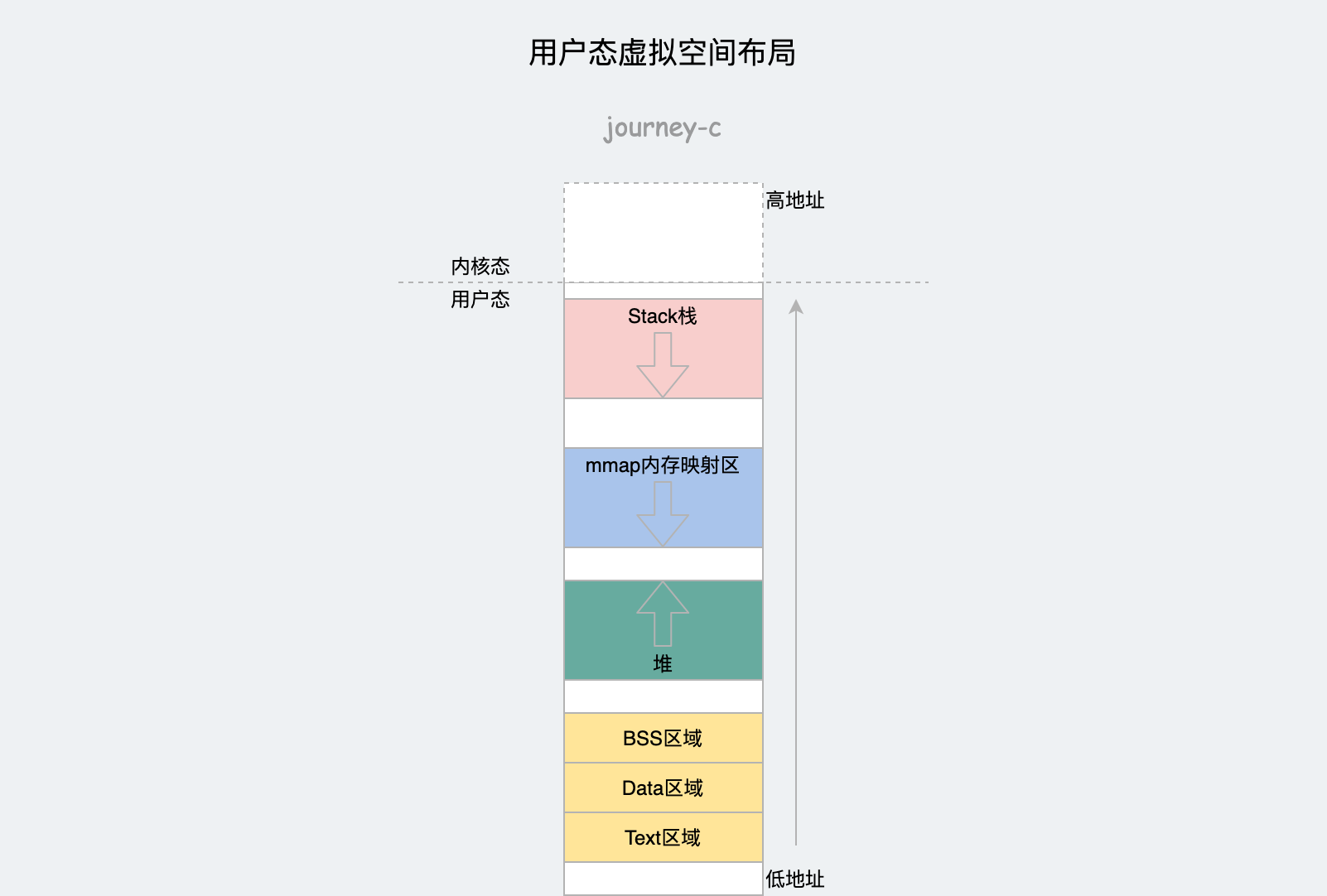
最上边是内核态,再往下过了分界线一段后是用户态的栈空间。进程操作时的入栈出栈都是操作的这块空间。除了空间还有两个CPU的寄存器辅助操作:
| 名称 | 32位名称 | 64位名称 |
|---|---|---|
| 栈顶指针寄存器 | ESP | rsp |
| 栈基地址指针寄存器 | EBP | rbp |
| 返回值寄存器 | EAX | rax |
基地址指针寄存器存放的值表示,本次操作数据是从哪开始放的。 栈顶指针寄存器存放的值表示,本次操作的数据放到哪了。 本次操作结束,有数据返回时,繁缛返回寄存器。
通过 栈空间 + 栈操作寄存器 组成了进程的逻辑意义上的栈。
下面通过函数调用的例子分析下栈的细节。
用户态函数栈
32位
函数调用的本质实际是代码的跳转。如果只有代码的跳转则不需要涉及太多东西,但是函数调用往往涉及参数的传递,以及跳过去再怎么跳过回来的问题。
结合交叉编译的32位汇编代码分析这个例子:A 调用 B,B 返回 A。
- Linux上交叉编译32位代码
// main.c
#include <stdio.h>
int B(int a, int b)
{
return a + b;
}
int A()
{
int a = 1;
int b = 2;
int c = a + b;
return B(a, b) + c;
}
int main(int argc, char* argv[])
{
printf("%d\n", A());
return 0;
}
/*
* sudo apt-get install build-essential module-assistant
* sudo apt-get install gcc-multilib g++-multilib
* cc -S -m32 main.c
*/
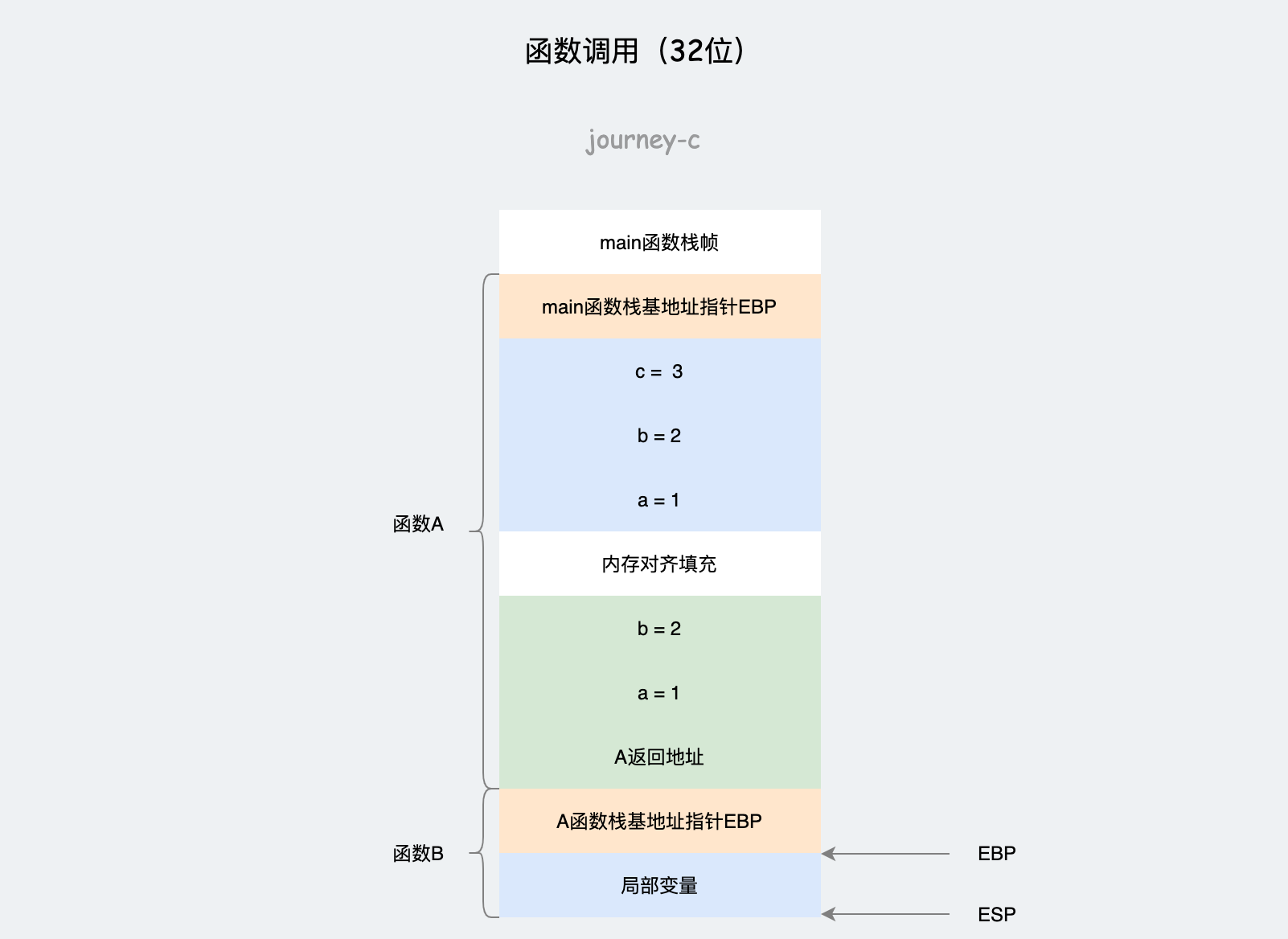
A函数栈帧中:
- 首先将main函数栈帧基地址ebp入栈
pushl %ebp - 然后开辟A函数的栈帧
movl %esp, %ebp - 然后存放A函数中局部变量
subl $16, %esp movl $1, -12(%ebp) movl $2, -8(%ebp) movl -12(%ebp), %edx movl -8(%ebp), %eax addl %edx, %eax movl %eax, -4(%ebp) - 然后调用B函数,先是参数入栈
pushl -8(%ebp) pushl -12(%ebp) - 调用B函数的call指令会顺便将A函数返回地址也入栈
call B
到此位置A函数的栈帧基本形成了,如上图,由栈底开始依次是上一个函数ebp,局部变量、下一个函数参数、返回地址。
局部变量和参数之间根据栈帧的长度会有一定的填充,保持内存空间与16字节对齐。
64位
64位和32位栈帧组成差不多,唯一的区别就是64位机器寄存器多了,函数参数前六个参数可以放在rax、rsi、rdx、rcx、r8d、r9d上。
// main.c
#include <stdio.h>
int B(int a, int b, int c, int d, int e, int f, int g)
{
return a + b + c + d + e + f + g;
}
int A()
{
int a = 1;
int b = 2;
int c = 3;
int d = 4;
int e = 5;
int f = 6;
int g = 7;
return B(a, b, c, d, e, f, g);
}
int main(int argc, char* argv[])
{
printf("%d\n", A());
return 0;
}
/*
* cc -S main.c
*/

64位系统中:
- 保存main函数的栈基地址指针寄存器
- 开辟A的栈帧,并且将局部变量a~g放入栈中
- 前六个参数入寄存器:rax、rsi、rdx、rcx、r8d、r9d。第七个参数入栈
- 调用B函数,然后返回结果,最后返回main函数
内核态函数栈
进程不光要在用户态运行,涉及系统调用以及其他情况时也要在内核态运行。在内核态运行时同样会涉及函数调用传参,这块布局不常见。
进程的stack变量的作用就是维护内核态的栈空间。源码中定义内核栈初始大小的变量为:THREAD_SIZE,
32位机器中定义如下,PAGE_SIZE=4KB,所以内核栈初始大小位8KB
#define THREAD_SIZE_ORDER 1
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
64位机器中定义如下,内核初始大小为16KB,并且要求起始地址与16KB对齐。
#ifdef CONFIG_KASAN
#define KASAN_STACK_ORDER 1
#else
#define KASAN_STACK_ORDER 0
#endif
#define THREAD_SIZE_ORDER (2 + KASAN_STACK_ORDER)
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
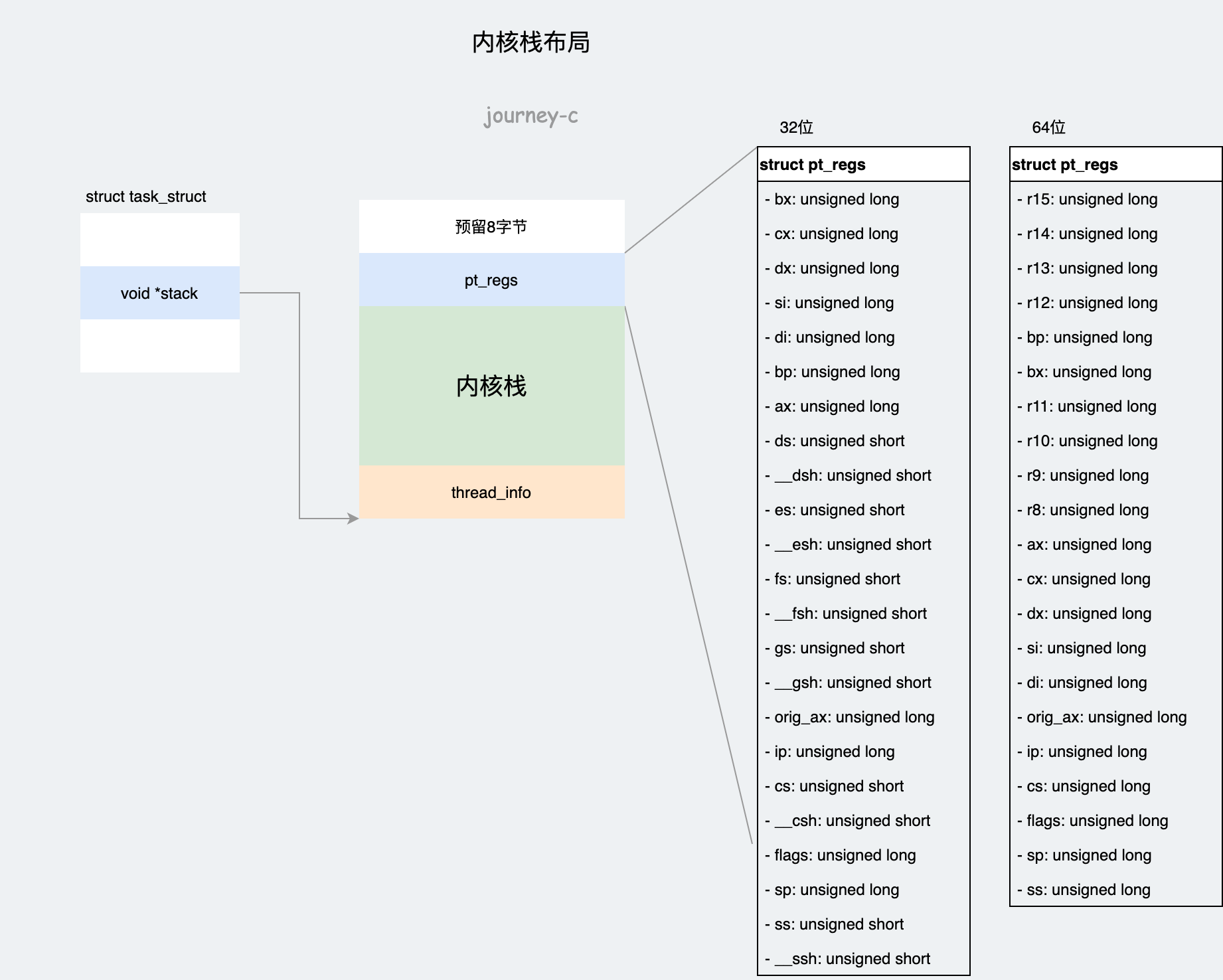
由高地址到低地址,首先是预留8字节,接下来是pt_regs结构体,存放的是寄存器信息,进程处于内核态时大部分情况都是从用户态进入的,所以要保存当时寄存器里值。仔细观察寄存器的顺序就会发现,汇编代码中使用寄存器的顺序就是按照变量在结构体中的顺序来的。
最后一部分是thread_info结构体,里面存放的也是进程信息,task_struct中存放的是通用信息,thread_info中存放的是与体系有关的东西。
内核栈使用时和用户态
用户态task_struct查找内核栈
上小结就提到了task_struct->stack指向了内核栈的最顶端(thread_info位置不是栈顶),所以用户态查找内核栈时就可以通过task_stack_page函数取stack的值。
使用task_pt_regs调用可以获得寄存器信息。
#define task_pt_regs(task) \
({ \
unsigned long __ptr = (unsigned long)task_stack_page(task); \
__ptr += THREAD_SIZE - TOP_OF_KERNEL_STACK_PADDING; \
((struct pt_regs *)__ptr) - 1; \
})
分析下过程:
- 首先是通过task_stack_page函数获取栈顶地址
- 然后向上移动了
THREAD_SIZE然后向下移动TOP_OF_KERNEL_STACK_PADDING
THREAD_SIZE之前讨论过,就是内核栈的长度,移动这个距离就是到达内核栈的最底端。TOP_OF_KERNEL_STACK_PADDING主要作用权限的限制。
#ifdef CONFIG_X86_32
# ifdef CONFIG_VM86
# define TOP_OF_KERNEL_STACK_PADDING 16
# else
# define TOP_OF_KERNEL_STACK_PADDING 8
# endif
#else
# define TOP_OF_KERNEL_STACK_PADDING 0
#endif
其中32位机器上是8,其余是0,其原因是,涉及权限变化时32位操作系统会保存堆栈信息(SS堆栈寄存器、ESP栈顶指针寄存器)。64位操作系统优化了这个问题。
内核栈查找用户态task_struct
直接通过get_current()获取当前运行的task_struct。task_struct的值直接放在Per CPU变量里。