
计算机的计算,一方面说的是进程、线程对于CPU的使用,另一方面是对于内存的管理。本文就是介绍Linux的内存管理。
在Linux中用户态是没有权限直接操作物理内存的,与硬件相关的交互都是通过系统调用由内核来完成操作的。Linux抽象出虚拟内存,用户态操作的只是虚拟内存,真正操作的物理内存由内核内存管理模块管理。本文通篇都在探索三个问题:
- 虚拟地址空间是如何管理的
- 物理地址空间是如何管理的
- 虚拟地址空间和物理地址空间是如何映射的
上述三个问题得到解决之后,我们就可通过一个虚拟地址空间找到对应的物理地址空间。我们首先来看一下Linux虚拟地址空间的管理。
1. 虚拟地址空间的管理
是不是用户态使用虚拟内存,内核态直接使用物理内存呢?
不是的,内核态和用户态使用的都是虚拟内存。
使用虚拟地址一个核心的问题,需要记录虚拟地址到物理地址的映射,最简单的方式是虚拟地址与物理地址一一对应,这样4G内存光是维护映射关系就需要4G(扯淡)。所以需要其他有效的内存管理方案。通常有两种:分段、分页。下面我们来一起分析一下这两种管理机制以及在Linux中是如何应用的。
分段

那我们先来看一下内存管理中分段机制的原理。

分段机制下虚拟地址由两部分组成,段选择子和段内偏移量。段选择子中的段号作为段表的索引,通过段号可以在段表找到对应段表项,每一项记录了一段空间:段基址、段的界限、特权级等。用段基址+段内偏移量就可以计算出对应的物理地址。
Linux中段表称为段描述符表,放在全局描述符表中,用GDT_ENTRY_INIT函数来初始化表项desc_struct。
下面是Linux中段选择子和段表的定义,看一下所有段表项初始化传入的参数中,段基址base都是0,这没有分段。事实上Linux中没有用到全部的分段功能,对于内存管理更倾向于分页机制。
#define GDT_ENTRY_KERNEL32_CS 1
#define GDT_ENTRY_KERNEL_CS 2
#define GDT_ENTRY_KERNEL_DS 3
#define GDT_ENTRY_DEFAULT_USER32_CS 4
#define GDT_ENTRY_DEFAULT_USER_DS 5
#define GDT_ENTRY_DEFAULT_USER_CS 6
DEFINE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page) = { .gdt = {
#ifdef CONFIG_X86_64
[GDT_ENTRY_KERNEL32_CS] = GDT_ENTRY_INIT(0xc09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xa09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc093, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER32_CS] = GDT_ENTRY_INIT(0xc0fb, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f3, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xa0fb, 0, 0xfffff),
#else
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xc09a, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xc0fa, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f2, 0, 0xfffff),
......
#endif
} };
EXPORT_PER_CPU_SYMBOL_GPL(gdt_page);
分页
分页机制和分段机制差不多,都是将物理地址分块。不同的是分段一般将内存大段大段的分割且每段大小一般不相同。而分页将物理内存分成一块块大小相同的页,一般大小为4KB。

例如页大小为4KB,只分一级,32位环境中虚拟地址为32位,$2^{32}/2^{12}=2^{20}$可以分1M个页,用20位可以表示页号,12位表示页内偏移。页表项大小为4B(32位),那么页表大小就是$1M*4B=4MB$,因为每个进程都有自己独立的虚拟地址空间,有100个进程的话光维护页表就需要100MB的空间,这个对于内核来说有点太大了。

Linux是如何解决页表太大的问题呢?
采用多级分页的策略才解决页表太大的问题。
32位环境中,一级分页和上边描述的一样,分成1M个4KB的页,由页表维护虚拟页号到物理页号的映射。内核在这次分页之后,又对页表进行分页。页表大小为4MB,我们在按照4KB一页进行分页,4KB包含页表项1K项。所以二级分页就是把页表1M的项按照1K项为一页分了1K页。
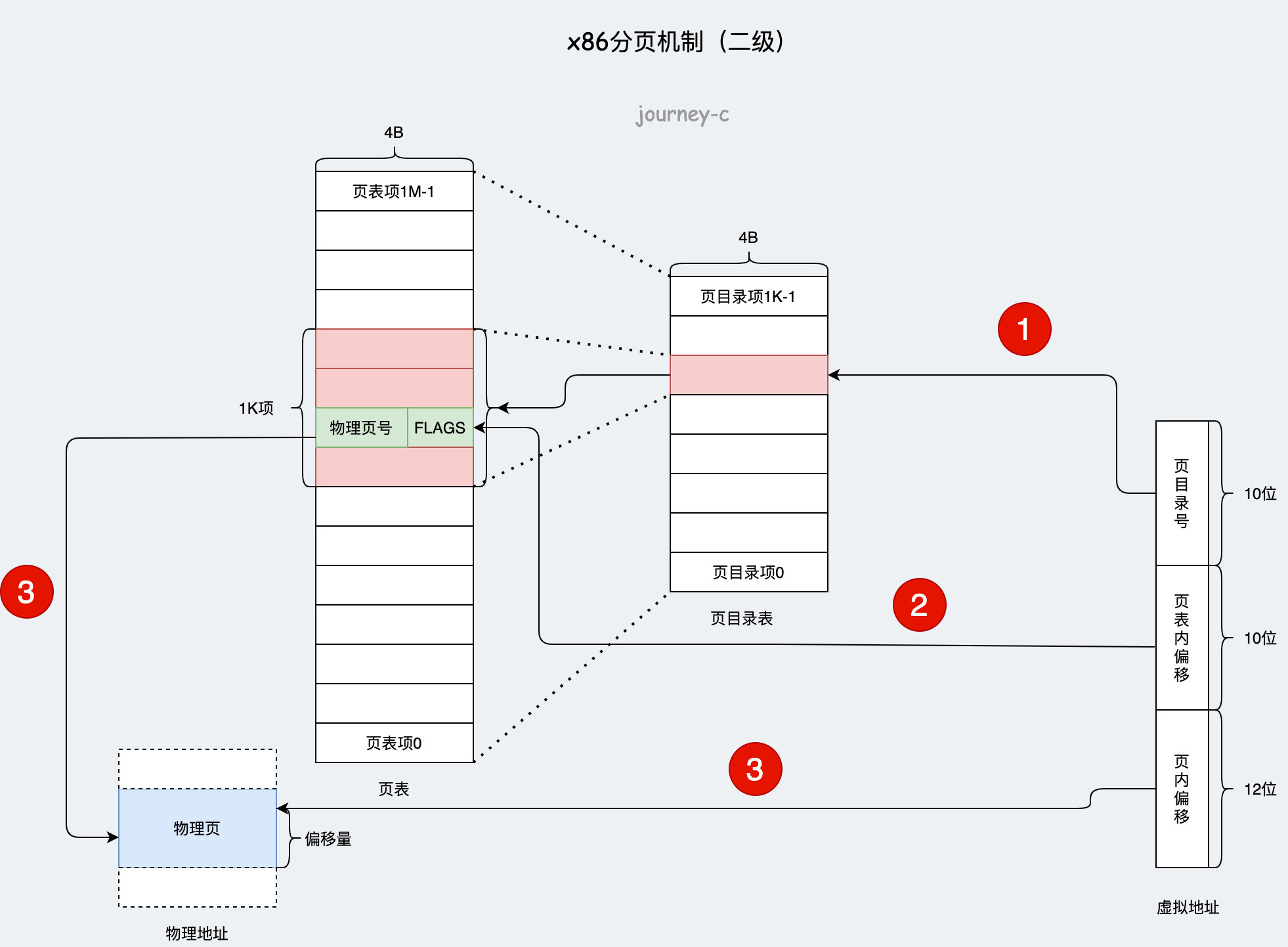
- 通过虚拟地址前10位的页目录号找到对应页目录项,这个页目录项管理了1K个页表项。
- 通过虚拟地址中10位的页表内偏移,从1K个页表项中定位到一个页表项。这个页表项里有物理页号和各种标志位。
- 物理页号+虚拟地址中后12位的页内偏移得到对应物理地址。
这样用于维护分页机制的额外空间就是页表(4MB)+ 页表目录(4KB),这不是比一级分页更高了吗?
实际不是的:
- 如果使用一级页表,那么每个进程都需要一个页表来维护虚拟地址空间,就是说100个进程需要额外400 MB的空间。
- 如果使用二级页表,每个进程必须的是一个4KB的页目录表。当然并不是每个进程都是用全部4GB内存的。所以4MB的二级页表不会全部使用,用到多少地址就建多少个页表项。所以实际需要额外空间为4KB+使用的页表项数量*4KB
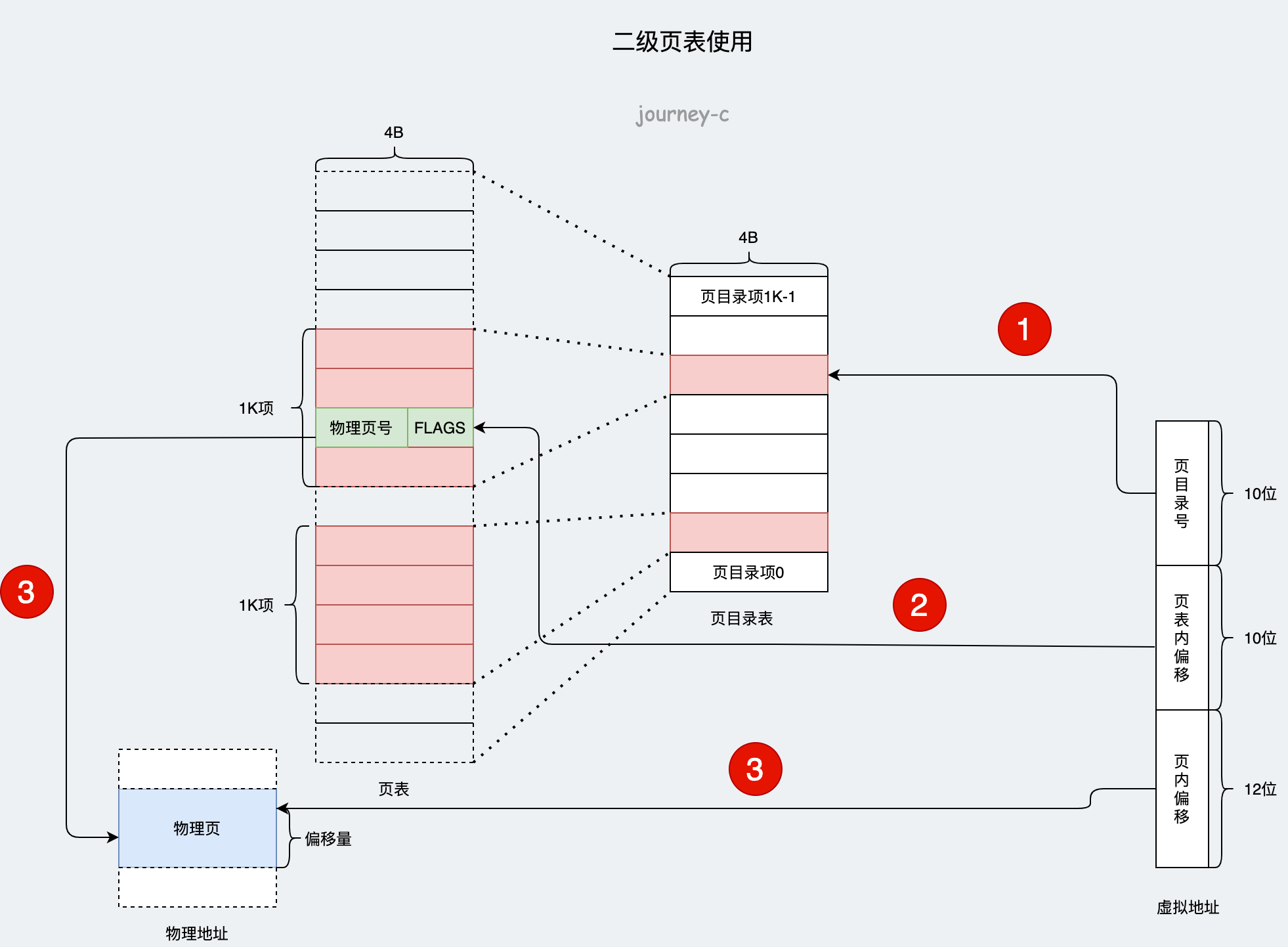
当然64位的环境中,二级页表就不够了,使用的是四级页表,包括全局页目录项 PGD(Page Global Directory)、上层页目录项 PUD(Page Upper Directory)、中间页目录项 PMD(Page Middle Directory)和页表项 PTE(Page Table Entry)

虽然多级分页解决了页表过大的问题,但是同时也增大了访问延时,由原来的一次访问内存,变为现在访问多次页表之后才能访问目的地址。
到目前为止,我们已经知道如何通过一个虚拟地址得到对应的物理地址。
2. 进程的虚拟地址空间
接下来我们再一起看一下进程内的虚拟地址空间是什么样的,Linux中没有进程线程的区别,用struct task_struct表示任务。那么我们可以分析struct task_struct中内存相关变量来分析进程的虚拟内存布局。
struct task_struct {
...
struct mm_struct *mm;
...
};
struct task_struct里面struct mm_struct来管理内存。
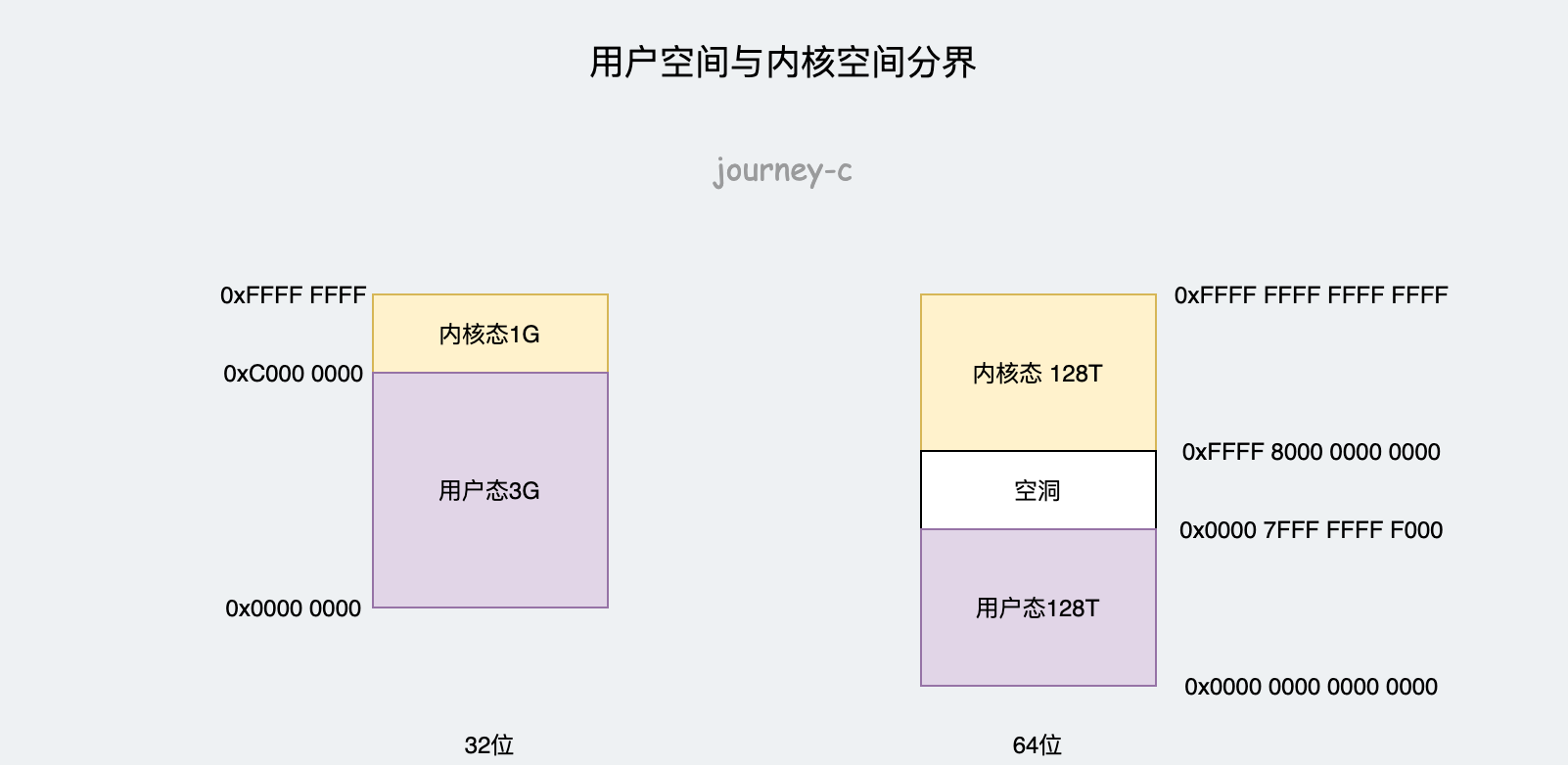
首先,既然分析用户态的基本布局,当然要知道用户态和内核态的界限在哪,struct mm_struct里面的task_size变量表示用户态空间的大小。
使用系统调用execve加载二进制文件的调用链是do_execve -> do_execveat_common -> bprm_execve -> exec_binprm -> search_binary_handler -> linux_binfmt的load_binary接口。load_binary接口实际是load_elf_binary。
load_elf_binary调用setup_new_exec。这个函数中会将task的mm_struct成员变量task_size 设置为TASK_SIZE。
32位环境中内核定义如下,TASK_SIZE为0xC0000000,用户空间默认3GB,内核空间1GB。
/*
* User space process size: 3GB (default).
*/
#define IA32_PAGE_OFFSET __PAGE_OFFSET
#define TASK_SIZE __PAGE_OFFSET
#define TASK_SIZE_LOW TASK_SIZE
#define TASK_SIZE_MAX TASK_SIZE
#define DEFAULT_MAP_WINDOW TASK_SIZE
#define STACK_TOP TASK_SIZE
#define STACK_TOP_MAX STACK_TOP
64位环境中虚拟地址只是用了48位,TASK_SIZE为 (1 « 47) 减去一页的大小为0x00007FFFFFFFF000。用户空间大概位128TB,内核空间也是128TB,且用户空间和内核空间之间留有空隙用于隔离。
#define TASK_SIZE_MAX ((_AC(1,UL) << __VIRTUAL_MASK_SHIFT) - PAGE_SIZE)
#define DEFAULT_MAP_WINDOW ((1UL << 47) - PAGE_SIZE)
/* This decides where the kernel will search for a free chunk of vm
* space during mmap's.
*/
#define IA32_PAGE_OFFSET ((current->personality & ADDR_LIMIT_3GB) ? \
0xc0000000 : 0xFFFFe000)
#define TASK_SIZE_LOW (test_thread_flag(TIF_ADDR32) ? \
IA32_PAGE_OFFSET : DEFAULT_MAP_WINDOW)
#define TASK_SIZE (test_thread_flag(TIF_ADDR32) ? \
IA32_PAGE_OFFSET : TASK_SIZE_MAX)
#define TASK_SIZE_OF(child) ((test_tsk_thread_flag(child, TIF_ADDR32)) ? \
IA32_PAGE_OFFSET : TASK_SIZE_MAX)
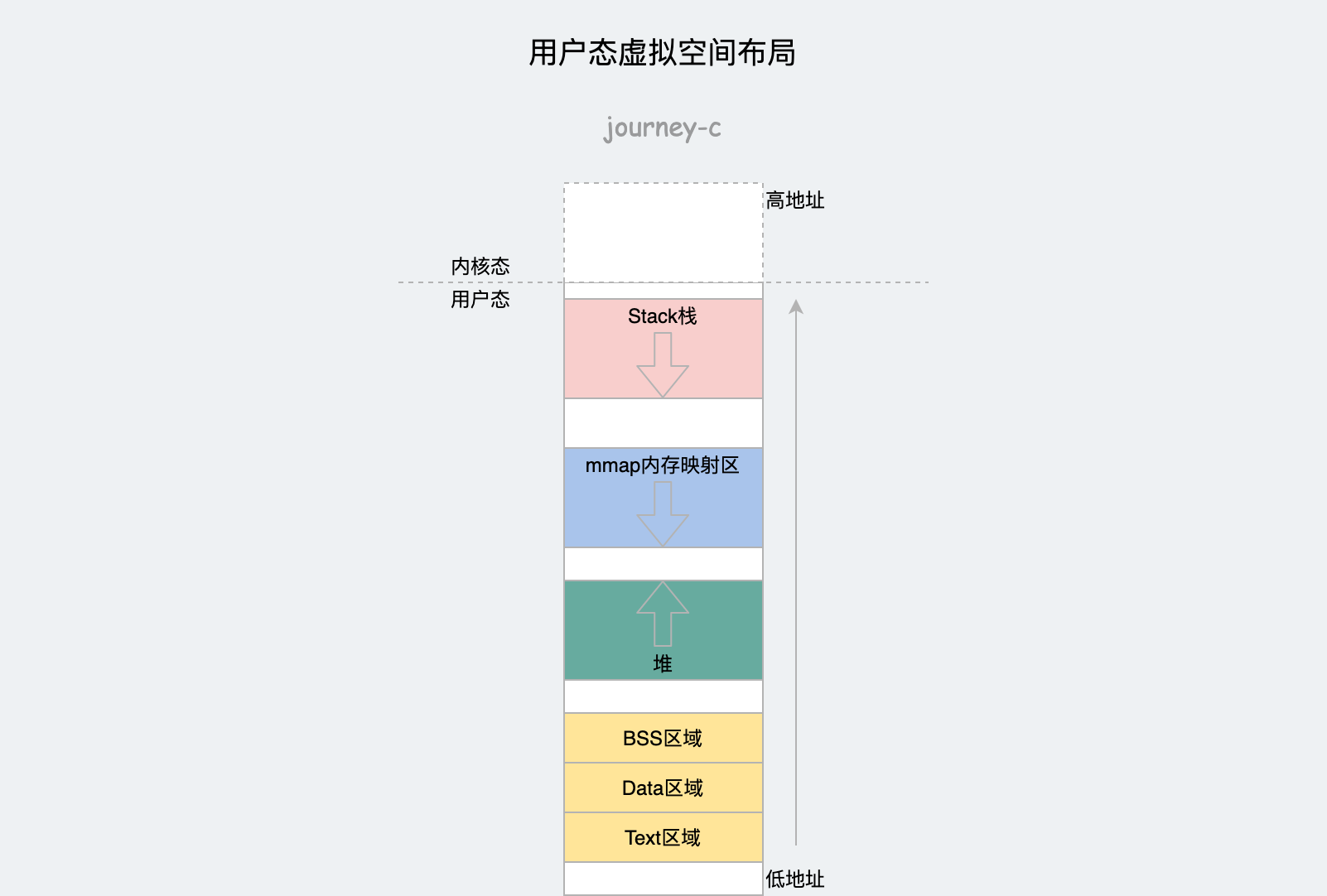
用户态
了解了用户空间和内核空间分界之后,我们先来看下用户空间。用户态虚拟内存布局如下,32位和64位区域和布局差别不大。
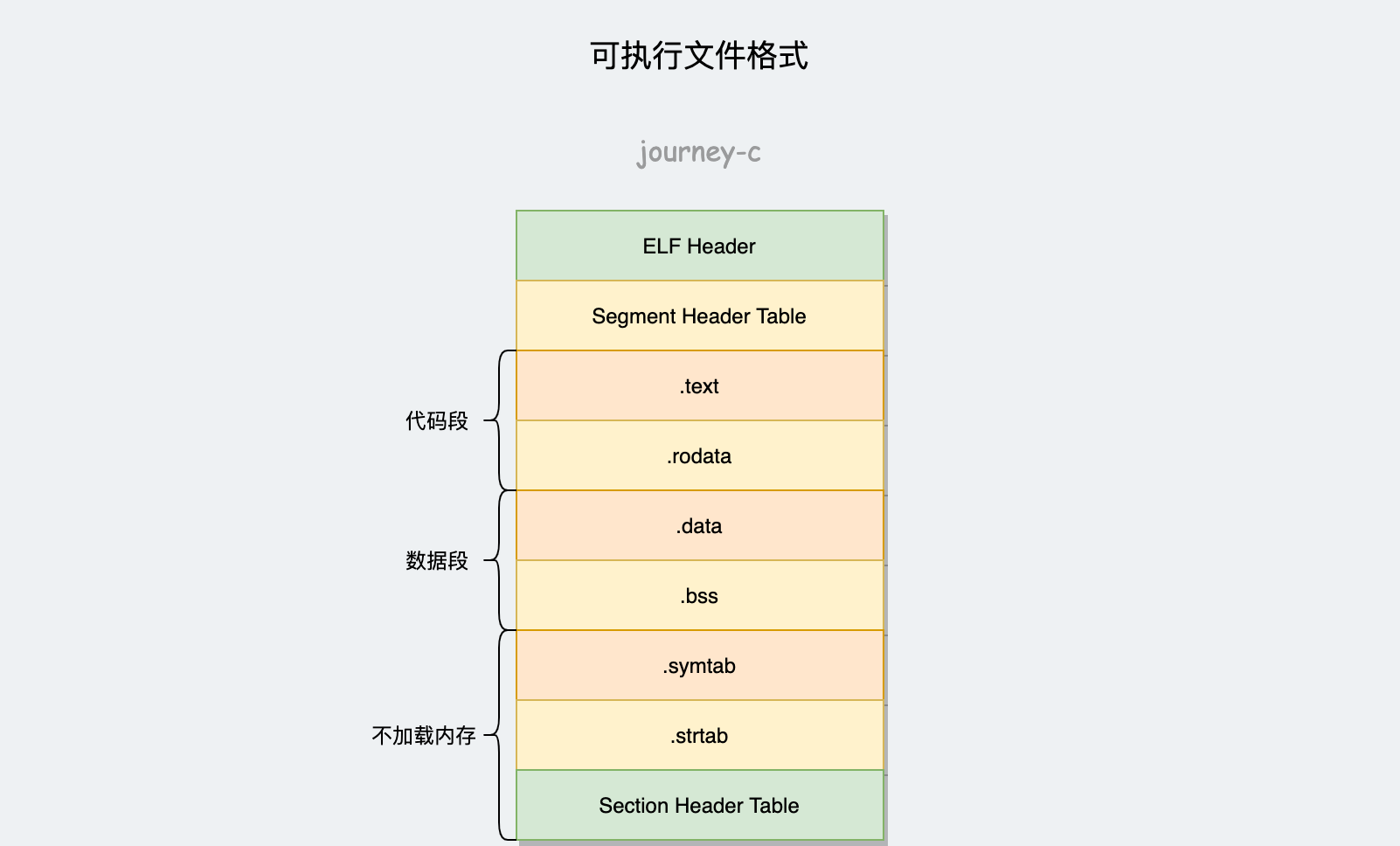
| 类型 | 字段名 | 用途 |
|---|---|---|
| struct vm_area_struct * | mmap | 内存中每个区域对应一个mmap,这些区域用链表连接起来 |
| struct rb_root | mm_rb | 红黑树,用来辅助操作mmap |
| unsigned long | mmap_base | 用于映射的内存起始位置 |
| unsigned long | task_size | 用户空间大小 |
| unsigned long | total_vm | 总共映射的页数 |
| unsigned long | locked_vm | 当内存吃紧,将个别页换到磁盘上,locaked_vm表示被锁定不能换出的页数 |
| unsigned long | pinned_vm | 不能换出也不能移动的页数 |
| unsigned long | data_vm | 存放数据页数 |
| unsigned long | exec_vm | 可执行文件占用的页数 |
| unsigned long | stack_vm | 栈占用的页数 |
| unsigned long | start_code, end_code, start_data, end_data | 代码段起始和结束位置,数据段起始和结束位置 |
| unsigned long | start_brk, brk, start_stack | 堆起始结束位置,栈起始位置(栈结束位置在SP寄存器中) |
| unsigned long | arg_start, arg_end, env_start, env_end | 参数列表起始和结束位置,环境变量起始和结束位置 |
函数load_elf_binary负责加载二进制,并且根据可执行文件内容初始化各个区域。
- 调用setup_new_exec设置struct mm_struct的mm_base参数(mmap内存映射区域),并且设置task_size的值。
- 调用setup_arg_pages设置栈的struct vm_area_struct结构,并设置参数列表起始位置arg_start的值,arg_start指向栈低start_stack的位置。
- 调用elf_map将可执行文件中的代码段映射到内存空间。
- 调用set_brk设置堆空间的struct vm_area_struct,并且初始化start_brk=brk(堆为空)。
- 如果有动态库,则调用load_elf_interp映射到内存映射区域。
- 给start_code, end_code, start_data, end_data赋值。
进程的用户态布局就变成下面这样。
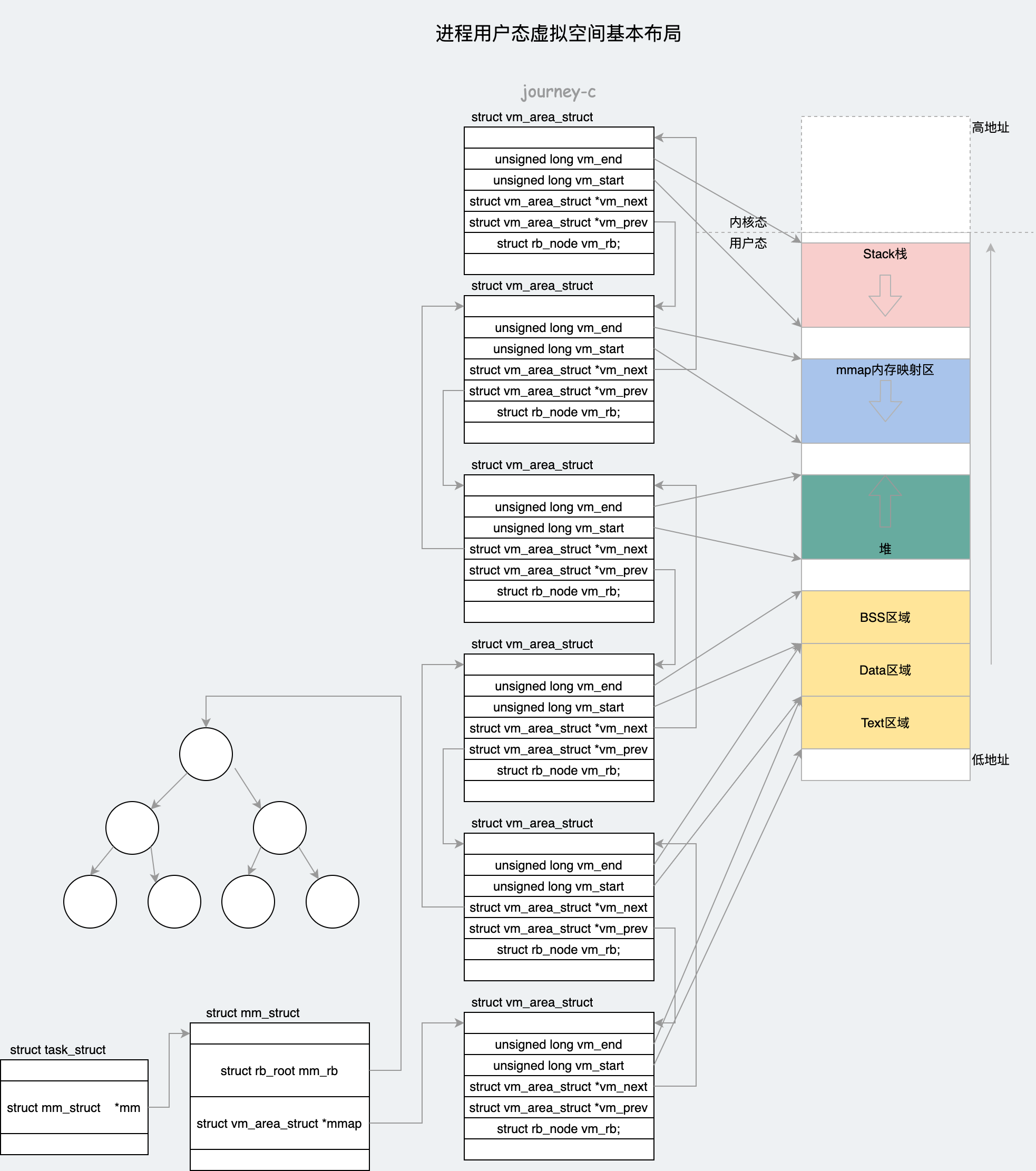
内存区域映射完之后,存在一下情况区域会发生变化:
- 用户调用malloc/free申请堆空间,小内存操作调用brk移动堆结束指针,大内存操作调用mmap。
- 创建临时变量或函数调用导致栈指针移动时对应栈区域也会移动。
这里简单看下堆内存操作brk的过程,mmap后边会讲解。
- 入口在SYSCALL_DEFINE1(brk, unsigned long, brk)。参数brk就是新堆顶的位置。
- 将参数堆顶位置brk和进程旧堆顶位置brk关于页对齐,如果对齐后两者相同说明变化量很小可以在同一页里解决。将mm_struct的brk指向新的brk即可。
- 如果两者对齐后不相同,说明操作跨页了,如果新brk小于旧的brk说明是释放内存,就调用__do_munmap将多余的页去掉映射。
- 如果新brk大于旧brk说明是申请内存,就调用find_vma在红黑树中找到下一个struct vm_area_struct的位置,看中间是否还能分配一个完整的页,分配不了就报错。如果能就更新各参数分配。
内核态
内核态的虚拟地址空间和某个进程没关系,所有进程共享同一个内核态虚拟地址空间。并且此时讨论的还是虚拟地址空间。前面分析用户态和内核态分界的时候讲了32位内核态是1GB,64位内核态是128TB。因为空间的数量级就差很大,可想而知布局也会有一定差别,毕竟32位太小了。我们先来分析一下32位内核态的布局。
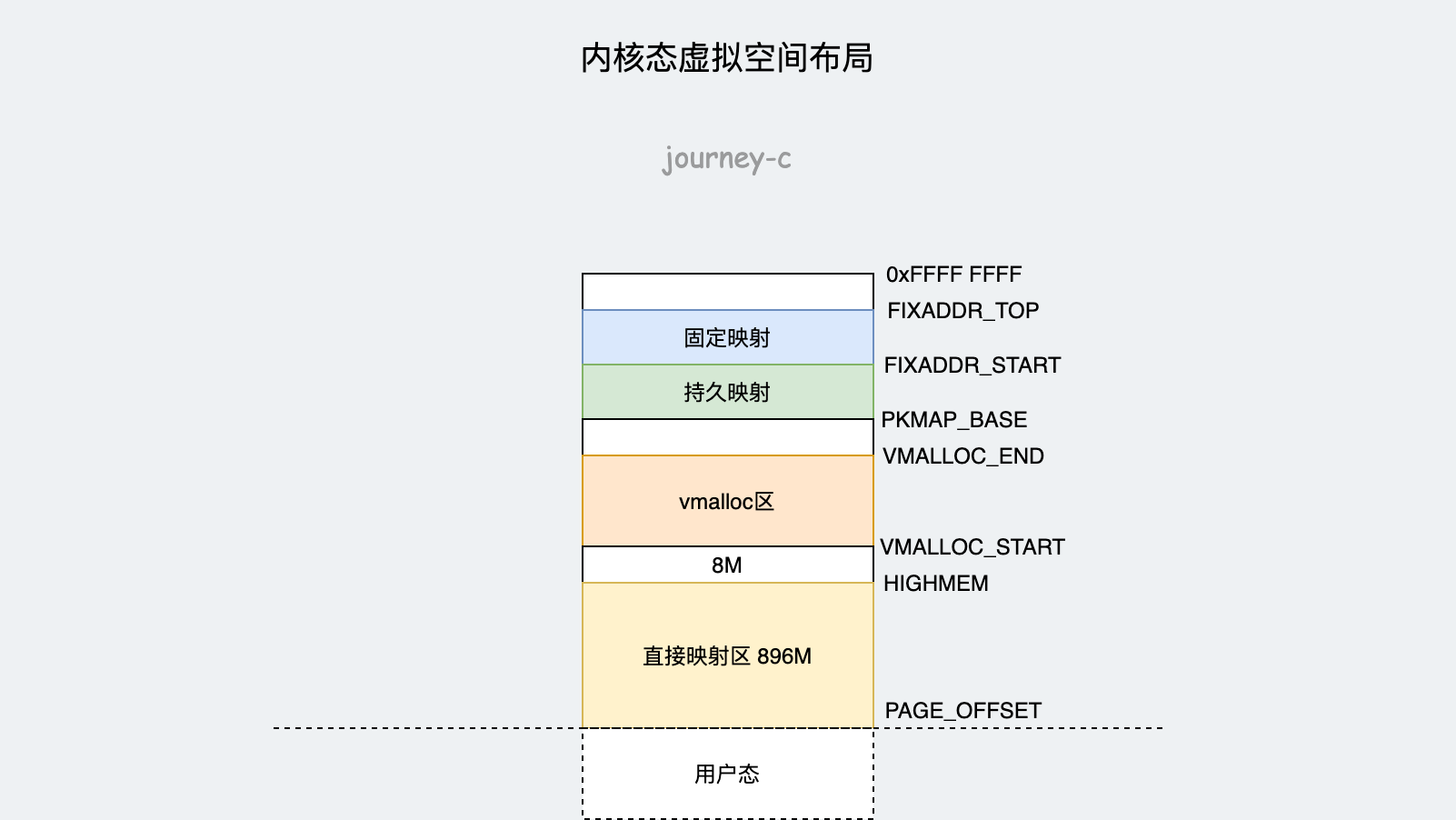
- 前896M为直接映射区,这部分地址连续,虚拟地址与物理地址映射关系较为简单,内核用了两个宏定义来转换地址#define __va(x),#define __pa(x)实际转换规则就是虚拟地址-PAGE_OFFSET(前面讲过用户空和内核空间分界)得到物理地址,物理地址+PAGE_OFFSET得到虚拟地址。直接映射区前1M空间开机处于实模式时会使用,内核代码从1M开始加载,然后就是全局变量、BSS等,另外内存管理的页表以及进程的内核栈都会放在这个区域。
- 接下来就是8M的空洞,用于捕捉内存越界。其他空洞也是这个原因。
- VMALLOC_START到VMALLOC_END成为动态映射空间,类似进程的堆,内核使用vmalloc进行动态申请内存的区域。
- PKMAP_BASE到FIXADDR_START是持久映射空间,通常为4M,内核使用alloc_pages获得struct page结构,然后调用kmap将其映射到这个区域。
- FIXADDR_START到FIXADDR_TOP为固定映射区域,留作特定用途。
64位的内核态布局就较为简单了,毕竟128TB太大不需要扣内存。
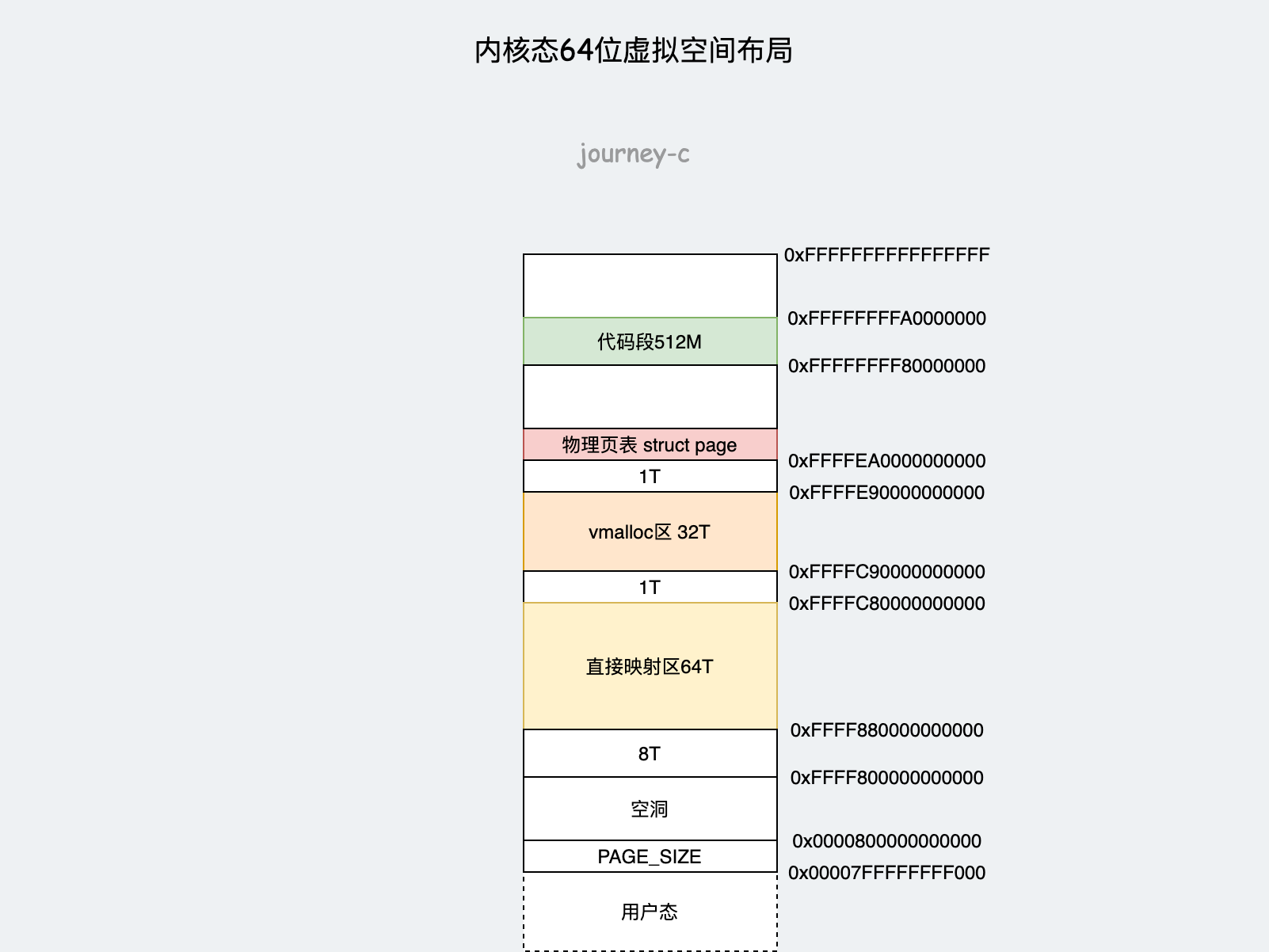
- 内核空间从0xffff800000000000开始,之后有8T空洞。
- 0xFFFF880000000000到0xFFFFC80000000000是直接映射区,同32位。
- 0xFFFFC90000000000到0xFFFFE90000000000是动态映射区,同32位。
- 然后就是存放物理页表,同32位持久映射区域。
3. 物理地址空间的管理
讲完了虚拟地址空间的管理,现在再来看一下Linux是如何管理物理内存的。
传统的x86架构的工作模式中,多处理器与一个集中存储器相连时,所有CPU都要通过总线去访问内存。也就是对称多处理器模式SMP(Symmetric multiprocessing)。

为了提高性能和扩展性,诞生了一种更高级的模式,非一致性内存访问NUMA(Non-uniform memory access)。这种模式下每个CPU有自己本地的内存,当本地内存不足时才会访问其他NUMA节点的内存。这样就提高了访问的效率。

值得注意的一点就是Mysql对NUMA支持不友好,NUMA在默认在本地CPU上分配内存,会导致CPU节点之间内存分配不均衡,当某个CPU节点的内存不足会使用Swap而不是直接从远程节点分配内存。经常内存还有耗尽,Mysql就已经使用Swap照成抖动,这就是"Swap Insanity”。所以单机部署Mysql的时候最好将NUMA关掉。
节点
接下来我们就看一下当前主流的模式NUMA,NUMA模式中内存分节点,每个CPU有本地内存,内核中用typedef struct pglist_data pg_data_t表示节点。我们来看一下这个结构体重点的变量。
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones; /* number of populated zones in this node */
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
struct page *node_mem_map;
#ifdef CONFIG_PAGE_EXTENSION
...
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
...
} pg_data_t;
- 节点ID,node_id。
- node_mem_map 就是这个节点的 struct page 数组,用于描述这个节点里面的所有的页。
- node_start_pfn 是这个节点的起始页号。
- node_spanned_pages 是这个节点中包含不连续的物理内存地址的页面数。
- node_present_pages 是真正可用的物理页面的数目。
- 节点内再将页分成区,存放在node_zones数组中。大小是MAX_NR_ZONES。
- nr_zones表示节点的区域数量。
- node_zonelists是备用节点和它的内存区域的情况。当本地内存不足时会使用到。
区域的类型如下:
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
- ZONE_DMA直接内存读取区域,DMA是一种机制,要把外设的数据读入内存或把内存的数据传送到外设,原来都要通过 CPU 控制完成,但是这会占用 CPU,影响 CPU 处理其他事情,所以有了 DMA 模式。CPU 只需向 DMA 控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,这样就可以解放 CPU。对于64位系统有两个DMA区域ZONE_DMA、ZONE_DMA32,后者只能被32位设备访问。
- ZONE_NORMAL直接映射区,内核虚拟地址空间讲过,就是地址加上一个常量与虚拟地址空间映射。
- ZONE_HIGHMEM高端内存区,64位系统是不需要的。
- ZONE_MOVABLE可移动区,通过将内存划分为可移动区和不可移动区来避免碎片。
- ZONE_DEVICE为支持热插拔设备而分配的Non Volatile Memory非易失性内存
区
内核将内存分区的目的是形成不同内存池,从而根据用途进行分配。内核使用struct zone表示区。区就是本节点一个个页集合了。我们再来看一下这个结构体。
struct zone {
...
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
...
unsigned long zone_start_pfn;
atomic_long_t managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
...
struct free_area free_area[MAX_ORDER];
unsigned long flags;
spinlock_t lock;
...
} ____cacheline_internodealigned_in_smp;
- zone_start_pfn表示这个区中第一页。
- spanned_pages表示和节点中的node_spanned_pages变量类似,都是不连续物理页数,就是终止页减去起始页(中间可能有空洞,但是不管)。
- present_pages实际物理页数量。
- managed_pages被伙伴系统管理的所有的 page 数目。
- pageset用于区分冷热页,前面将分段机制时说过80386架构CS、DS等段寄存器由单纯表示段地址升级为段选择子和段描述符缓存器。就是说有些经常被访问的页会被缓存在寄存器中,被缓存的就是热页,这个变量就是用于区分冷热页。
- free_area空闲页。
页
然后就到了最基本的内存单元——页,内核使用struct page表示物理页。结构体中有很多union,用于不同模式时的表示。主要有两种模式,1. 整页分配使用伙伴系统、2. 小内存分配使用slab allocator技术。
页的分配
页的分配有两种情况:
- 按页分配
- Slab分配(通常分配大小小于一页)
按页分配
使用伙伴系统分配,struct zone中的free_area数组每个元素都是一个链表首地址,每条链表有1、2、4、8、16、32、64、128、256、512 和 1024 个连续页。也就是说最多可以分配4MB的连续内存,每个页块的地址物理页地址是页块大小的整数倍。
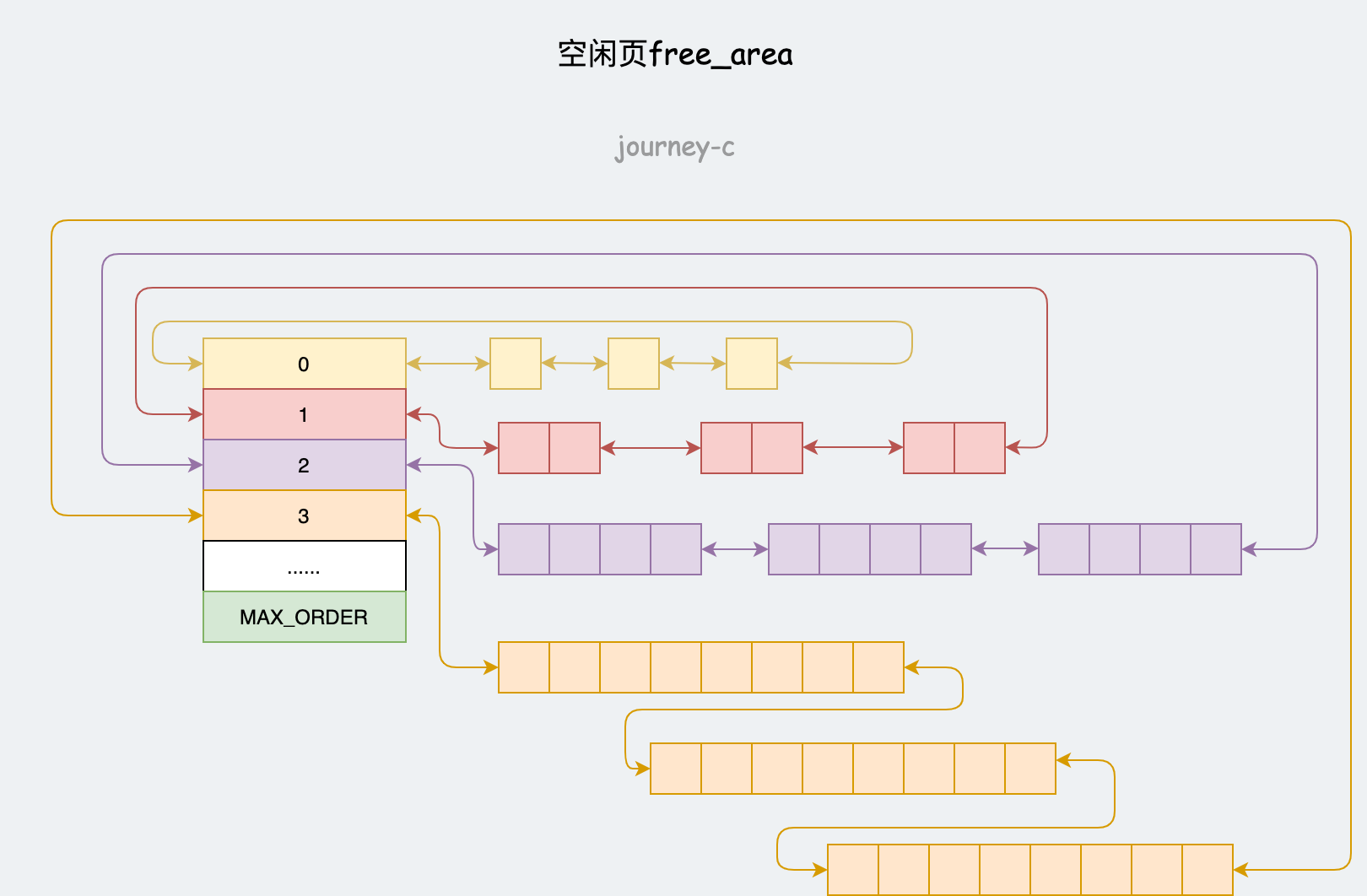
- alloc_pages调用alloc_pages_current。
- alloc_pages_current中根据参数gfp判断分配什么类型的页,GFP_USER用户空间页,GFP_KERNEL内核空间页,GFP_HIGHMEM高端内存页。参数order表示分配$2^{order}$个页。之后调用__alloc_pages_nodemask。
- __alloc_pages_nodemask是伙伴系统的核心方法,大概逻辑就是先看当前区空闲页是否足够,不够就看备用区,遍历每个区时,比如要分配128个页,就会从128个页的块往上找,例如128没有,256有,就将256分割称128和128,一个用于分配,另一个放入128页为一块的链表中。
释放页使用free_pages,参数addr和order分别为page地址和要是释放的页数,释放页数为$2^{order}$。
Slab分配
内核以及用户空间几乎很少用到按页分配的情况,普遍使用都是像malloc那样小段内存申请,并且操作十分频繁。这种频繁的操作通常会使用空闲链表,空闲链表缓存被释放的结构,下次分配是直接从链表抓取而不是申请。
内核中,空闲链表面临的主要问题是不能全局控制,当可用内存紧缺时,内核无法通知每个空闲链表收缩从而释放一些内存。事实上内核根本不知道存在哪些空闲链表。为了弥补这一缺陷,Linux内核提供了Slab层。Slab分配器来充当通用数据结构缓存层的角色,以感知所有缓存链表状态。1
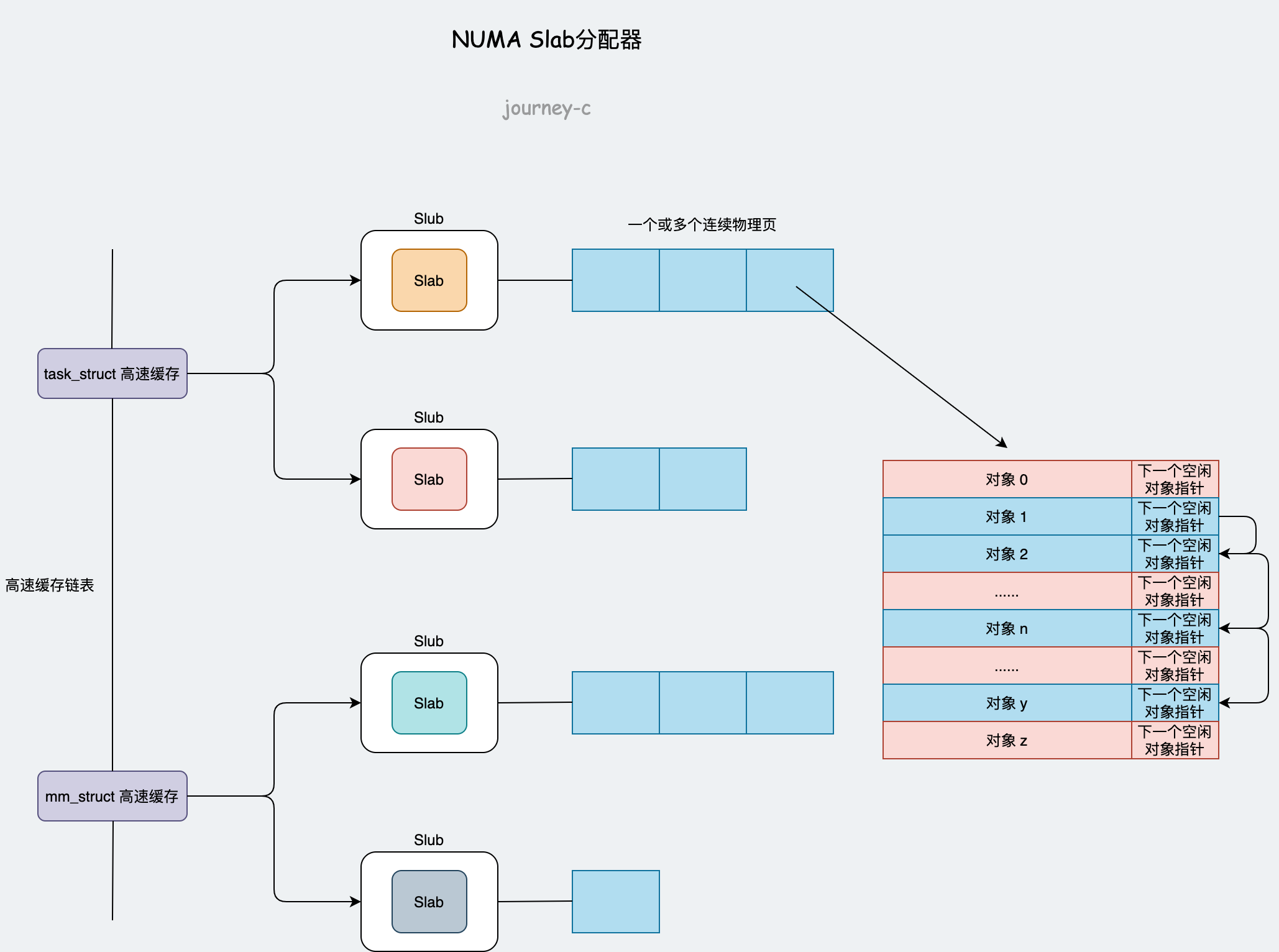
Slab分配模式中:
- 每个结构体对应一个高速缓存,由kmem_cache_create函数创建,由kmem_cache_destroy函数销毁。例如进程线程的结构体struct task_struct对应高速缓存为task_struct_cachep,进程虚拟内存管理结构体struct mm_struct对应高速缓存为mm_cachep,每个高速缓存都使用struct kmem_cache表示。这里的struct kmem_cache是
include/linux/slub_def.h下的,高速缓存中有多个slab。
内核最开始只有slab,后来开发者对slab逐渐完善,就出现了slob和slub。slob针对嵌入式等内存有限的机器,slub针对large NUMA系统的大型机。
- 每个slab里面存放了若干个连续物理页用于分配,物理页按照结构体大小分割。工程师通过kmem_cache_alloc申请结构体,通过kmem_cache_free释放结构体(放回)。
先分析一下高速缓存struct kmem_cache。
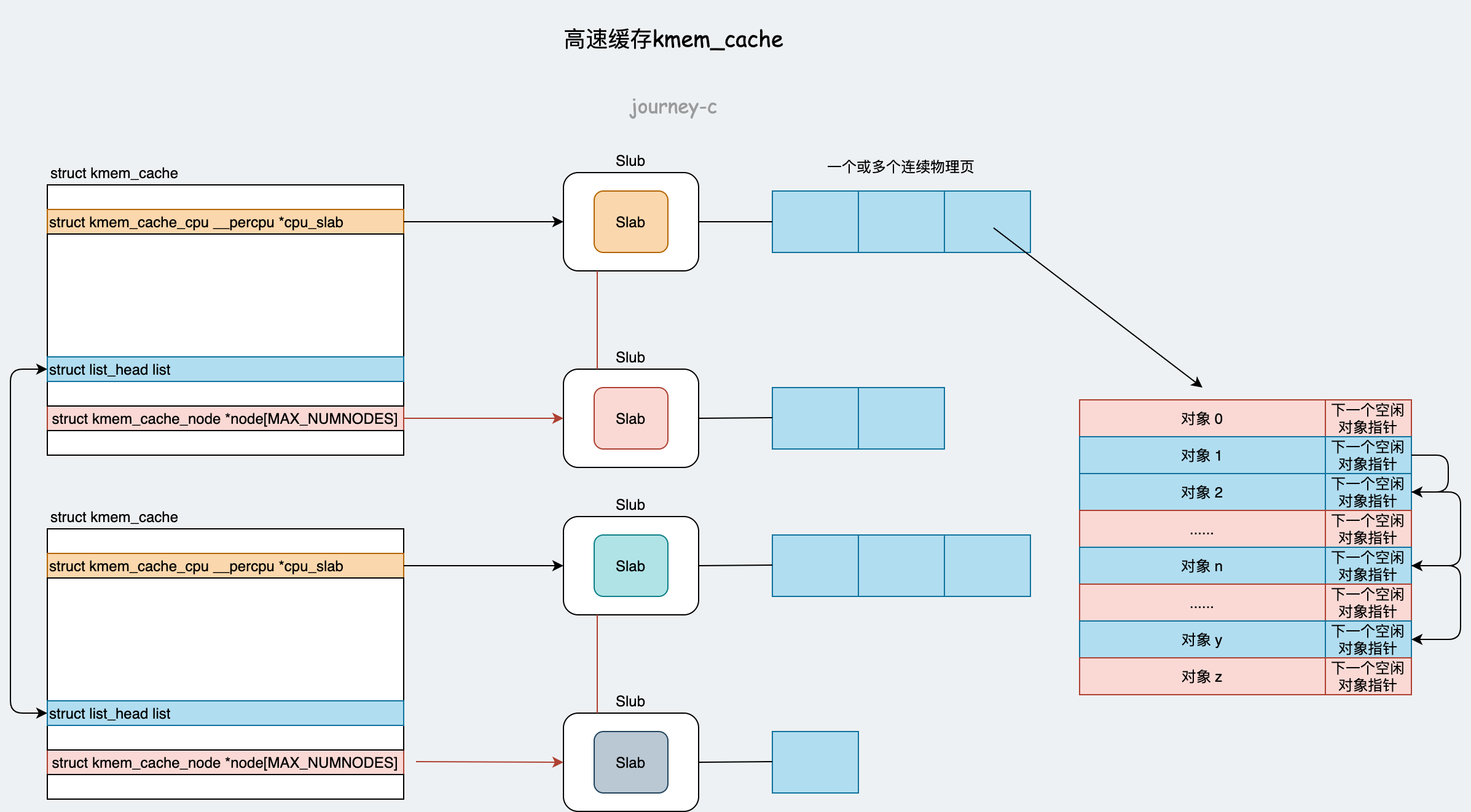
- cpu_slab 是每个CPU本地缓存。
- void **freelist 空闲对象链表
- struct page *page 所有连续的物理页
- struct page *partial 部分分配的物理页,这是备用的。
- list 是高速缓存所在链表。
- node[MAX_NUMNODES] 是该高速缓存所有的slab的数组,每个slab都有一个状态(1.满的,2.空的,3.半满),本地缓存不够时根据这个状态去找其他的slab。另外还用链表维护着这三个状态的slab。
- struct list_head slabs_partial 存放半满的slab
- struct list_head slabs_full 存放已满的slab
- struct list_head slabs_free 存放空的slab
下面我们根据调用系统调用execve加载二进制文件的例子来看一下NUMA环境中Slab分配内存的完整过程。既然要加载二进制文件,那么进程结构体struct task_struct中内存管理变量struct mm_struct当然要申请了。
调用链为execve->do_execve -> do_execveat_common -> alloc_bprm -> bprm_mm_init -> mm_alloc -> allocate_mm -> kmem_cache_alloc
到这里可以看到高速缓存申请的接口kmem_cache_alloc,其中参数struct kmem_cache是struct mm_struct对应的高速缓存。再看一下这个函数做了哪些事情:
- 调用slab_alloc,紧接着调用slab_alloc_node。
- slab_alloc_node中首先在CPU本地缓存cpu_slab中分配,这就是注释中说的快速通道,分配到了直接返回,否则就调用__slab_alloc去其他slab中分配,这就是普通通道。
- __slab_alloc中首先再尝试从本地缓存cpu_slab中分配,没有的话就跳到new_slab先考虑从本地缓存cpu_slab备用物理页partial中分配,再没有的话就调用new_slab_objects去其他slab中分配了。如果在没有就只能在申请物理页了。
到现在已经说完slab分配对象的逻辑了,但是还有一个问题,就是空闲缓存的回收,由于有了slab层内核已经可以感知所有空闲链表的状态了,所以回收问题是可以解决的。初始化时内核就会注册回收任务,每隔两秒进行一次检查,检查是否需要收缩空闲链表。调用链是cpucache_init -> slab_online_cpu -> start_cpu_timer 将cache_reap注册为定时回调函数。
页换出
不管32位还是64位操作系统,不一定非得按照操作系统要求装内存条,例如32位最大4G虚拟地址空间,但是用户就买了2G怎么办?超过2G的虚拟地址空间不用了吗?不会的,现在几乎所有操作系统都是支持SWAP,就是将不活跃的物理页暂时缓存到磁盘上。
一般页换出有两种方式:
- 主动(当申请内存时,内存紧张就考虑将部分页缓存到磁盘)
- 被动(Linux 内核线程kswapd定时检查是否需要换出部分页)
- 调用链为balance_pgdat -> kswapd_shrink_node -> shrink_node -> shrink_node_memcgs
- shrink_node_memcgs就是处理页换出的函数了,里面有个LRU表,根据最近最少未使用的原则换出。
4. 内存映射
上边讲完了虚拟地址空间和物理地址空间是如何管理的,还剩下最后一个问题,这俩是怎么映射的?其实虚拟地址不止可以和物理内存映射,还可以和文件等映射。物理内存只是一种特殊的情况。
用户态映射
首先来看一下用户态映射方式。
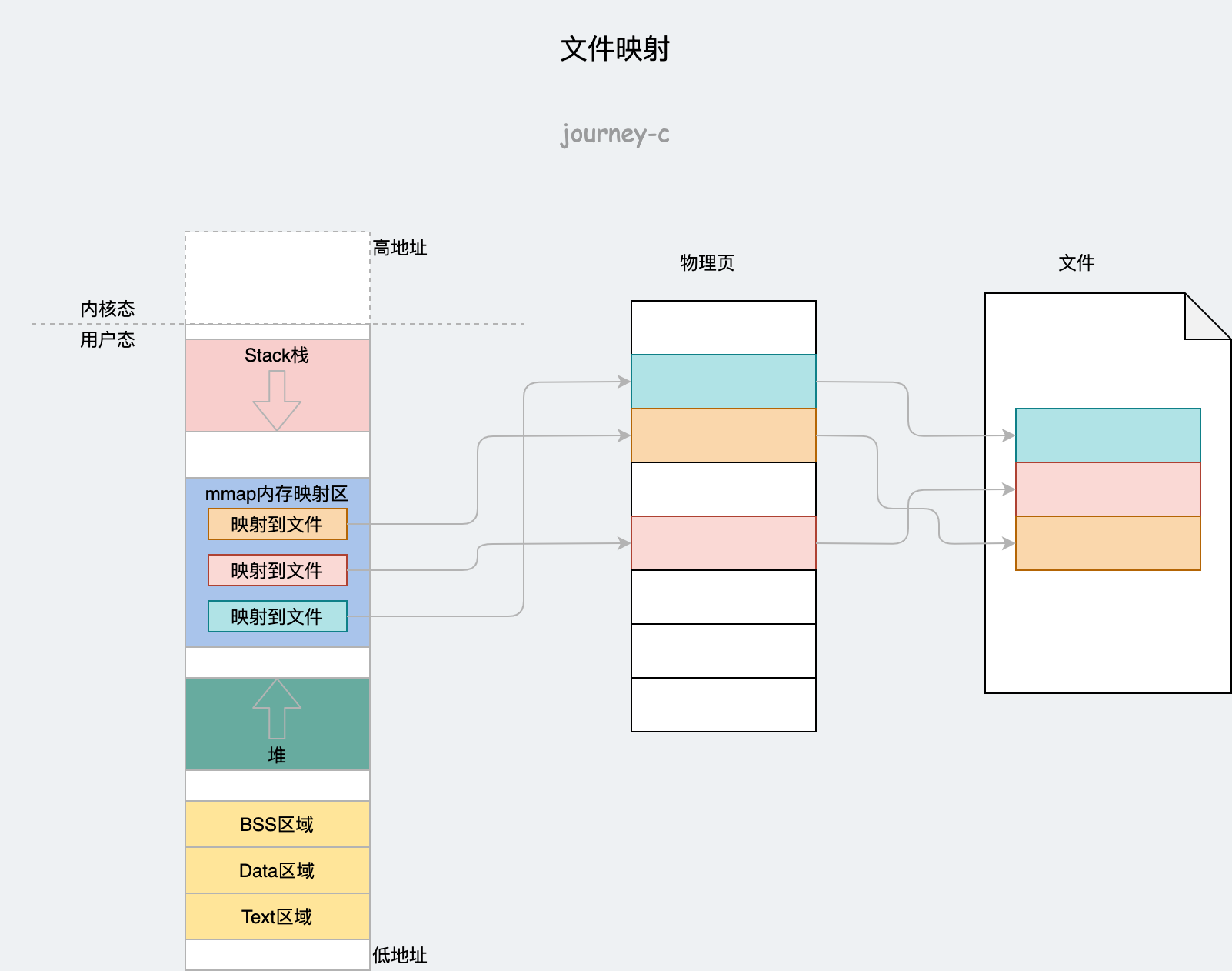
我们先来分析一下mmap。
- 调用ksys_mmap_pgoff参数有fd,通过fd找到对应struct file。接下来调用vm_mmap_pgoff -> do_mmap。
- do_mmap中:
- 首先调用get_unmapped_area在进程地址空间里找到一个没映射的区域(那棵红黑树)。
- 然后调用mmap_region将文件映射到这个区域,并且调用call_mmap执行file->f_op->mmap接口把这个区域的struct vm_area_struct结构的内存操作接口换成那个文件的操作函数,也就是说对这段虚拟内存读写,就相当于执行该文件的读写函数。如果是ext4文件系统对应的mmap接口就是ext4_file_mmap。ext4_file_mmap中执行内存操作替换为文件操作vma->vm_ops = &ext4_file_vm_ops;
- 然后将struct vm_area_struct挂到进程的struct mm_struct上。
- 现在文件已经和虚拟内存地址有映射了。还没有与物理内存产生关系,而物理内存的映射是用到的时候才映射。
缺页
访问某个虚拟地址时,如果没有对应的物理页就会触发缺页中断handle_page_fault这里会判断是内核态缺页还是用户态缺页,我们先来看用户态的,会调用do_user_addr_fault。这个函数中:
- 找到缺页区域对应的struct vm_area_struct。
- 然后调用handle_mm_fault->__handle_mm_fault。
- __handle_mm_fault中首先会创建前面一直提的页表,然后调用handle_pte_fault。
- handle_pte_fault中有三种情况:
- PTE表为空,说明是缺页(新的)
- 如果映射到物理内存就调用do_anonymous_page。
- 如果映射到文件就调用do_fault。
- PTE表不为空,说明页表创建过了,是被换出到磁盘的就调用do_swap_page。
- PTE表为空,说明是缺页(新的)
一个个分析,首先看映射到物理页的函数do_anonymous_page:
- 调用pte_alloc分配一个页表。
- 页表有了,就要申请一个物理页放到页表项里了,调用链是alloc_zeroed_user_highpage_movable -> __alloc_zeroed_user_highpage -> alloc_page_vma -> alloc_pages_vma -> __alloc_pages_nodemask。又看到熟悉的函数了__alloc_pages_nodemask就是前边说过的伙伴系统核心函数。
- 调用mk_pte创建一个页表项并把物理页放进去,最后调用set_pte_at将页表项放入页表。至此页表里面有对应物理页了,虚拟地址就有映射了。
再来看下映射到文件的函数do_fault:
- do_fault也有几种不同情况但最终都会调到__do_fault。
- __do_fault中会调用vma->vm_ops->fault接口,之前文件映射是说过在缺页之前已经将内存操作接口换成文件操作接口了,所以如果是ext4文件系统,这里的vm_ops就应该是ext4_file_vm_ops,也就是调用了ext4_filemap_fault。紧接着调用filemap_fault。
- filemap_fault首先调用find_get_page查找一下物理内存里事先有没有缓存好的,如果找到了就调用do_async_mmap_readahead从文件中预读一些数据到内存。没有的话就调用pagecache_get_page分配一个物理页并且把物理页加到LRU表里,然后调用struct address_space *mapping->a_ops->readpage接口将文件内容缓存到物理页中。ext4文件系统readpage接口对应ext4_readpage,这个函数又调用到ext4_readpage_inline -> ext4_read_inline_page。
- ext4_read_inline_page中首先调用kmap_atomic映射到内核的虚拟地址空间得到虚拟地址kaddr,本来的目的是将物理内存映射到用户虚拟地址空间,但是从文件读取内容缓存到物理内存又不能用物理地址(除了内存管理模块其他操作都得是虚拟地址),所以这里kaddr只是临时虚拟地址,读取完再把kaddr取消就行。
最后一种是交换空间类型的,函数do_swap_page,swap类型的和映射到文件的差不多,都是需要从把磁盘文件映射到内存。
- 首先调用lookup_swap_cache查看swap文件在内存有没有缓存页,有就直接用,没有就调用swapin_readahead将swap文件读到内存页中缓存,再调用mk_pte创建页表项,调用set_pte_at将页表项放入页表。
- 读swap文件过程和上一步映射到文件的差不多。
- 调用swap_free释放掉swap文件。
处理完缺页之后,物理页有内容、进程空间有页表,接下来就可以通过虚拟地址找到物理地址了。
为了加快映射速度,我们引进了TLB专门来做地址映射的硬件,缓存了部分页表。查询时先查快表TLB查到了直接用物理内存,查不到再到内存访问页表。
内核态映射
首先内核页表和用户态页表不同,内核页表在初始化时就创建了。内核初始化时将swapper_pg_dir赋值给顶级目录pgd。swapper_pg_dir指向顶级目录init_top_pgt。
系统初始化函数setup_arch调用load_cr3(swapper_pg_dir)刷新TLB说明页表已经构建完了。
实际初始化在arch/x86/kernel/head_64.S中。
#if defined(CONFIG_XEN_PV) || defined(CONFIG_PVH)
SYM_DATA_START_PTI_ALIGNED(init_top_pgt)
.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE_NOENC
.org init_top_pgt + L4_PAGE_OFFSET*8, 0
.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE_NOENC
.org init_top_pgt + L4_START_KERNEL*8, 0
/* (2^48-(2*1024*1024*1024))/(2^39) = 511 */
.quad level3_kernel_pgt - __START_KERNEL_map + _PAGE_TABLE_NOENC
.fill PTI_USER_PGD_FILL,8,0
SYM_DATA_END(init_top_pgt)
SYM_DATA_START_PAGE_ALIGNED(level3_ident_pgt)
.quad level2_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE_NOENC
.fill 511, 8, 0
SYM_DATA_END(level3_ident_pgt)
SYM_DATA_START_PAGE_ALIGNED(level2_ident_pgt)
/*
* Since I easily can, map the first 1G.
* Don't set NX because code runs from these pages.
*
* Note: This sets _PAGE_GLOBAL despite whether
* the CPU supports it or it is enabled. But,
* the CPU should ignore the bit.
*/
PMDS(0, __PAGE_KERNEL_IDENT_LARGE_EXEC, PTRS_PER_PMD)
SYM_DATA_END(level2_ident_pgt)
#else
SYM_DATA_START_PTI_ALIGNED(init_top_pgt)
.fill 512,8,0
.fill PTI_USER_PGD_FILL,8,0
SYM_DATA_END(init_top_pgt)
#endif
缺页
内核空间缺页同样会调用handle_page_fault。
5. 总结
- Linux虚拟地址空间采用分页机制,多级页表来减小页表占用空间。其原因就是越往后的页表项没用到的可以不用建。
- 物理地址管理:
- 内核管理单元管理。主流采用NUMA模型,每个CPU有本地内存(节点),本地内存根据用途再分区,每个区里就是物理页集合。
- 物理页申请时:
- 大内存按页分配通过伙伴系统
- 小内存通过slab分配器。那个结构体对应一个高速缓存,结构体申请释放都通过高速缓存,高速缓存里有很多slab,每个CPU又一个本地slab。slab里面就是很多待分配的结构体了。
- 物理内存紧张时会换出部分页面到磁盘上,也就是swap文件。
- 地址映射
- 虚拟地址映射到物理地址
- 虚拟地址映射到文件
- 用到虚拟地址是会检查是否有对应物理地址没有的话,就缺页。
- 虚拟地址映射到物理地址的缺页——分配物理页。
- 虚拟地址映射到文件的缺页——分配物理页,加载部分数据到物理页。
- 物理地址映射到磁盘swap文件——分配物理页,将swap文件加载进来。