1. 文件系统简介
Linux平台万物皆文件,这句话实际是在夸Linux出色的虚拟文件系统,Linux将所有设备抽象为文件,与设备的数据交互抽象为文件的I/O。
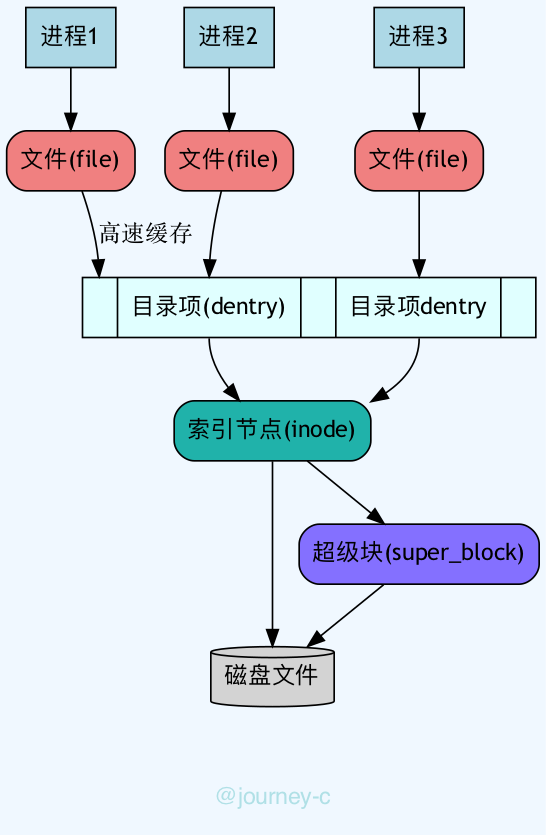
Linux的虚拟文件系统大概分为四块:
- 超级块
- 文件系统(ext3,ext4以及windows上的NTFS、FAT32、FAT16等)
- 内核结构对应super_block,对应操作对象super_operations。
- 索引节点
- 操作系统以块为单位对磁盘操作(块是扇区大小的整数倍)。索引节点记录了文件在磁盘上所有的物理块(文件内容),以及其他信心(更新时间,操作时间等)。
- 内核结构对应inode,对应操作对象inode_operations。
- 目录项
- 可以理解为文件的路径(不是目录,Linux上目录也是文件),进程操作文件时通过目录项找到实际文件。
- 内核结构对应dentry,对应操作对象dentry_operations。
- 文件
- 由进程打开的文件。
- 内核结构对应file,对应操作对象file_operations
通常服务里例如socket,pipe等对象的read,write实际就是file对应的file_operations的操作,而本文讲解I/O相关事情。
2. 几种I/O模型
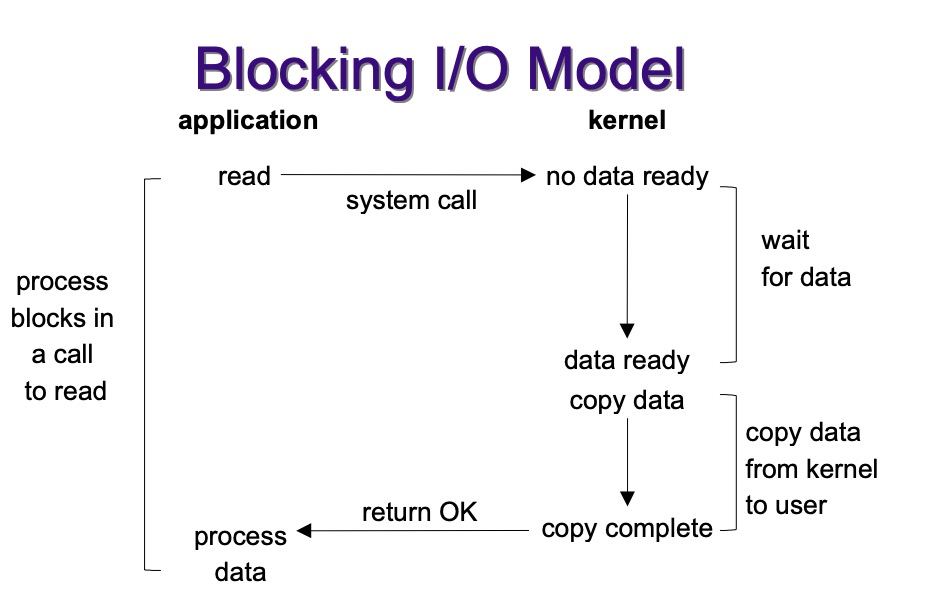
2.1 Blocking I/O
- 传统的阻塞I/O,对一个文件描述符操作(FD)时,如果操作没有响应就会一直等待,直到内核有反馈。缺点就是单线程一次只能操作一个FD。
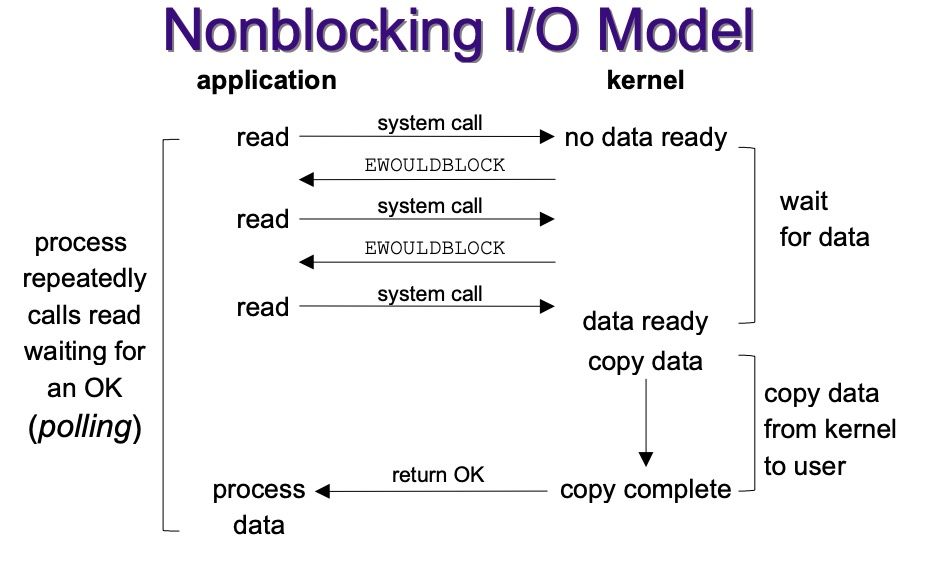
2.2 Nonblocking I/O
- 非阻塞I/O,对FD操作时,如果内核没反馈不会一直等待。非阻塞I/O会将所有FD放入FD set,一直轮询所有FD,直到有反馈的。缺点就是每次轮询时没有事件的FD也会被操作,浪费CPU。
2.3 Signal Driven I/O
- 信号驱动I/O的基本原理就是首先注册signal handler,当FD有事件到来时,内核会像进程发送信号,然后应用进程执行signal handler。缺点就是,编程难度高,信号处理起来复杂。
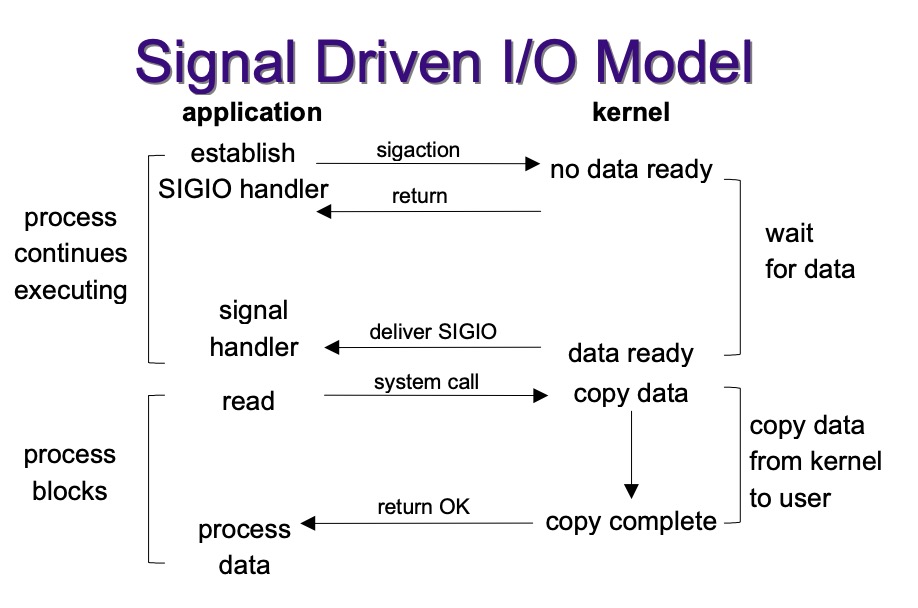
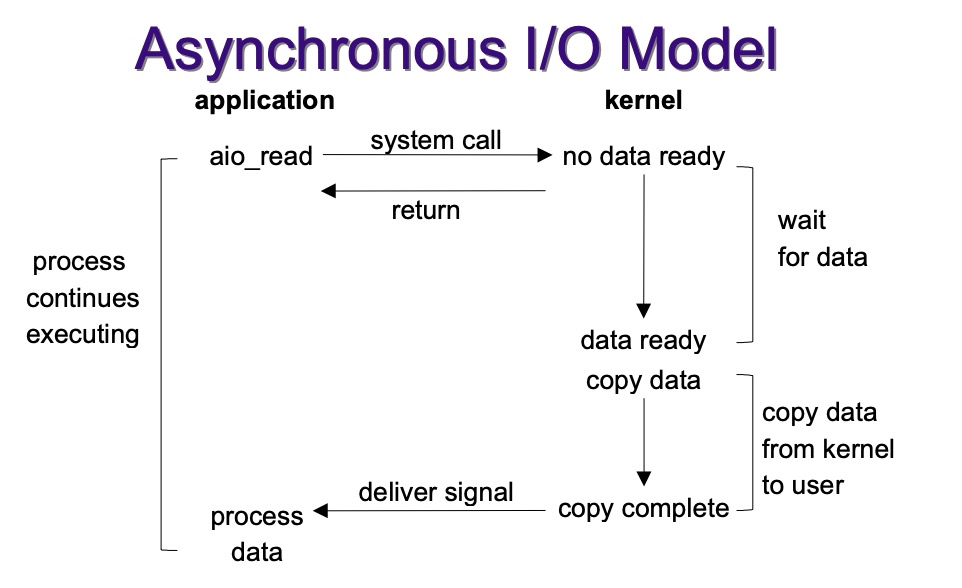
2.4 Asynchronous I/O
- 异步I/O和信号驱动I/O都是异步的,区别是:信号驱动I/O是FD满足条件时内核通知应用程序可以进行I/O了,而异步I/O是应用程序将I/O操作交给内核,当内核做完之后再通知应用程序I/O做完了。缺点是异步的并发量不好控制。
2.5 I/O Multiplexing
- 多路复用实际不是一个技术而是一个理念,在I/O多路复用之前就有通讯线路的频分复用和时分复用,大概就是合理的安排每个单位使用资源的时间和位置,看起来所有单位一起在使用原本只能允许少量单位同时使用的资源。
- Linux的I/O多路复用机制就是本文要讲的内容了。I/O多路复用就是将所有的FD注册到内核,然后当哪个FD可用时,那个会通知应用程序可用。
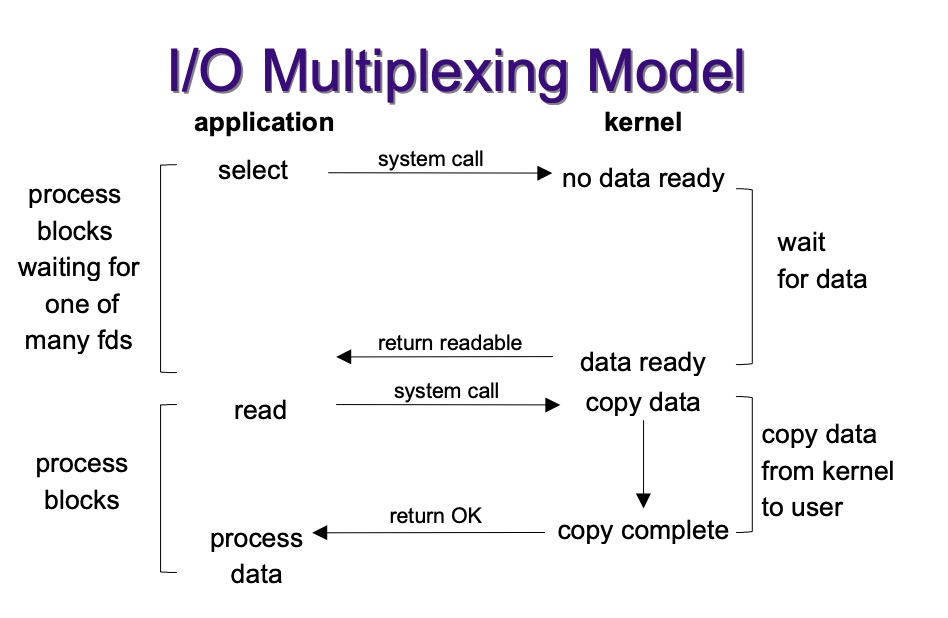
应用程序使用Linux提供的I/O多路复用机制都是通过系统调用使用的。最初Linux只提供了Select,在哪个服务端fd使用数量普遍不高的年代是够用的,后来随着网络的发展,1024个FD的限制已经不够用了,所以Linux提供了Poll,Poll只优化了存储结构,Select使用BitMap来存储FD,Poll使用数组来存储FD,不再限制数量,但是遍历时间复杂度还是$O(lg^N)$。终于在Linux 2.5.44版本,epoll闪亮登场,这是现在普遍使用的I/O多路复用机制。
3. Select
3.1 使用
Select是Linux最初提供的I/O多路复用函数。下面是libc库使用select的调用接口。
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
void FD_SET(int fd, fd_set *set);
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
Select总共三部分参数
- 传入FD(文件描述符)最大的+1
- 传入的FD,分三类
- 1). 监听读
- 2). 监听写
- 3). 监听异常
- 如果一直没有满足条件的fd,最多等多久(超时时间)
select用一个__FD_SETSIZE位的BitMap表示输入参数,__FD_SETSIZE默认为1024。因为没有1024位那么长的数,所以用一个数组表示,因为数组元素地址连续,所以实际就是一个1024位的数,比如第1位为1,表示这次输入有fd1(标准输出fd)。这个地方也限制了select最多支持1024个fd,并且fd的号码不能大于等于1024。

解释完fd_set的构造,FD_SET、FD_CLR等操作也就明白了,FD_SET(d, s)就是d是几号fd就将s的第几位置1,其他的类似。
3.2 实现
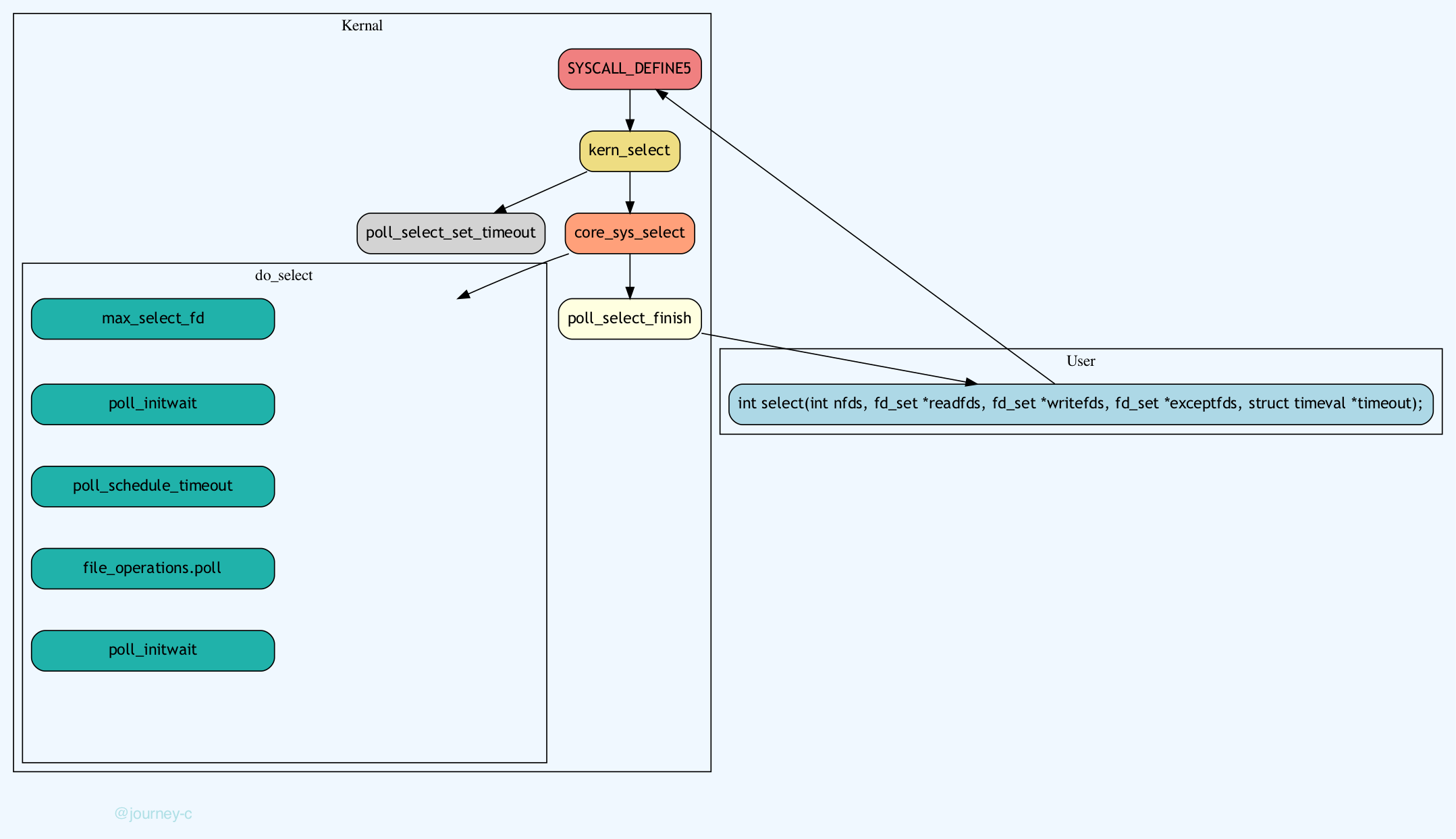
Linux的select函数是通过系统调用的机制提供给用户,我们来一起看一下Select的流程:
- 系统调用函数入口在SYSCALL_DEFINE5,可能是历史原因想保留这个接口,所以这个函数没做事情直接调用了kern_select。
- Select传入的时间是一个相对时间,kern_select判断如果时间参数不为空的话,就调用poll_select_set_timeout将相对时间转化为绝对时间(准确的几点几分几秒),然后就调用core_sys_select
- core_sys_select主要的工作就是为Select工作分配资源空间。
- 获取rcu锁,check一下第一个参数n是不是比进程最大可打开文件描述符数还大,如果还大的话修正n为最大可打开文件描述符数。释放rcu锁,rcu实际就是延迟更新,读操作不需要获取锁,只需要标记一下还有用户在读。写操作时拷贝一份数据,更新副本,当所有没有读者读旧数据的时候再将副本数据更新到原始数据上。
- 接下来就是给输入的三个变量fds.in, fds.out, fds.ex,保存结果的三个变量(fds.res_in, fds.res_out, fds.res_ex)分配存储空间,先从栈分配,栈空间不够时从堆分配。
- 资源分配结束后就调用do_select开始真正的检查每个FD是否可用。
- do_select是select的核心,流程如下:
- 首先调用max_select_fd找出传入FD的最大值+1,比较一下参数n是不是比最大FD+1还大,如果是就修正n为最大FD+1(
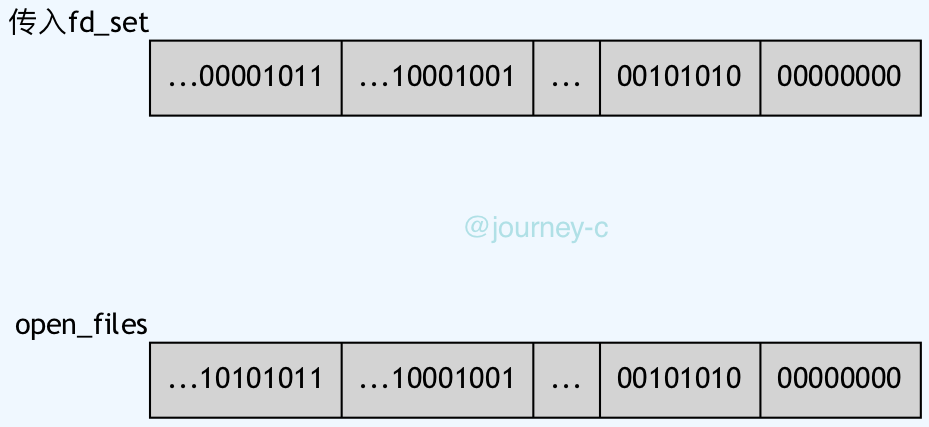
这里之所以总是将n修正为最大值+1,是因为do_select遍历范围是[0,n)),顺便检查下,传入的FD是不是有已关闭或者未打开的,如果有就报错EBADF:- 传入fd_set是long的数组,openfiles也是long的数组,因为之前n根据线程最大打开文件数修正过,所以通过(n/(long的位数))可以最高位可以比较的数组下表,然后fd_set数组的那一位根据(n % (long的位数))来去掉不满足条件的FD
- 然后就从最高位开始fd_set和open_file做AND操作,第一个匹配的就是最大FD。
-
- 调用poll_initwait初始化poll_wqueues(维护select/poll任务的主要struct),并且将__pollwait注册为poll_table的proc函数,file_operations->poll会调用poll_wait将此时所在线程(task)放入队列,poll_wait对调用__poll_wait,这个_poll_wait此时注册的函数。主要作用就是将任务放入队列,以及做一些其他任务。
- 如果timeout不为空,调用poll_schedule_timeout设置超时时间。
- 重复遍历所有fd_set:
- 这个循环是个死循环,跳出条件为:
- 超时时间到(如果设置了超时时间)。
- 线程被唤醒。
- 当前线程被信号唤醒。
- 调用fdget获取fd对应的file结构体。
- 调用vfs_poll,获取file的事件mask,如果有in,out,ex就放入对应结果的fd_set中。
- vfs_poll最终会调用file_operations的poll函数获取FD的事件状态mask,vfs_poll会调用file_operations->poll函数检查FD的事件,如果没有就调用poll_wait将线程放入等待队列。
- 调用fdput释放fd对应file结构体。
- 如果本次遍历一个有事件的FD也没有就调用cond_resched出让CPU,并且把线程状态设为INTERRUPTIBLE(睡眠可打断状态),休眠直到被唤醒。
- 等到有事件回调,就会重新遍历FD集合这次肯定有事件了,如果超时或者被信号唤醒也有相应操作。
- 这个循环是个死循环,跳出条件为:
- 首先调用max_select_fd找出传入FD的最大值+1,比较一下参数n是不是比最大FD+1还大,如果是就修正n为最大FD+1(
- do_select将可用FD返回之后,调用set_fd_set拷贝回用户空间。
- 如果传入参数的BitsMap一开始是分配在堆上的就释放调。
- 调用poll_select_finish将剩余时间拷贝回用户空间。
3.3 小结
select的流程简单来讲就是,将FD通过BitsMap传入内核,轮询所有的FD通过调用file->poll函数查询是否有对应事件,没有就将task加入FD对应file的待唤醒队列,等待事件来临被唤醒。(例如网卡来数据了)
- select使用BitsMap来传入和接受FD,每次调用都会在用户空间和内核空间之间拷贝。
- select的BitsMap限制只能监听FD 0~1023。
- 轮询的方式监听所有FD,$O(n)$的复杂度
4. Poll
4.1 使用
随着互联网的发展Select 1024个FD的限制已经不满足众多服务了,于是出现了Poll,不再用BitsMap来传入FD,取而代之用动态数组传入FD,但获取事件状态的方式还是轮询。
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
- 1.fds: 传入fd集合,由pollfd构成
-
- fd: 文件描述符
-
- events: 监听事件
-
- revents: 返回FD是因为什么事件返回的
-
- 2.nfds: fds的长度
- 3.timeout: 超时时间,单位毫秒
4.2 实现
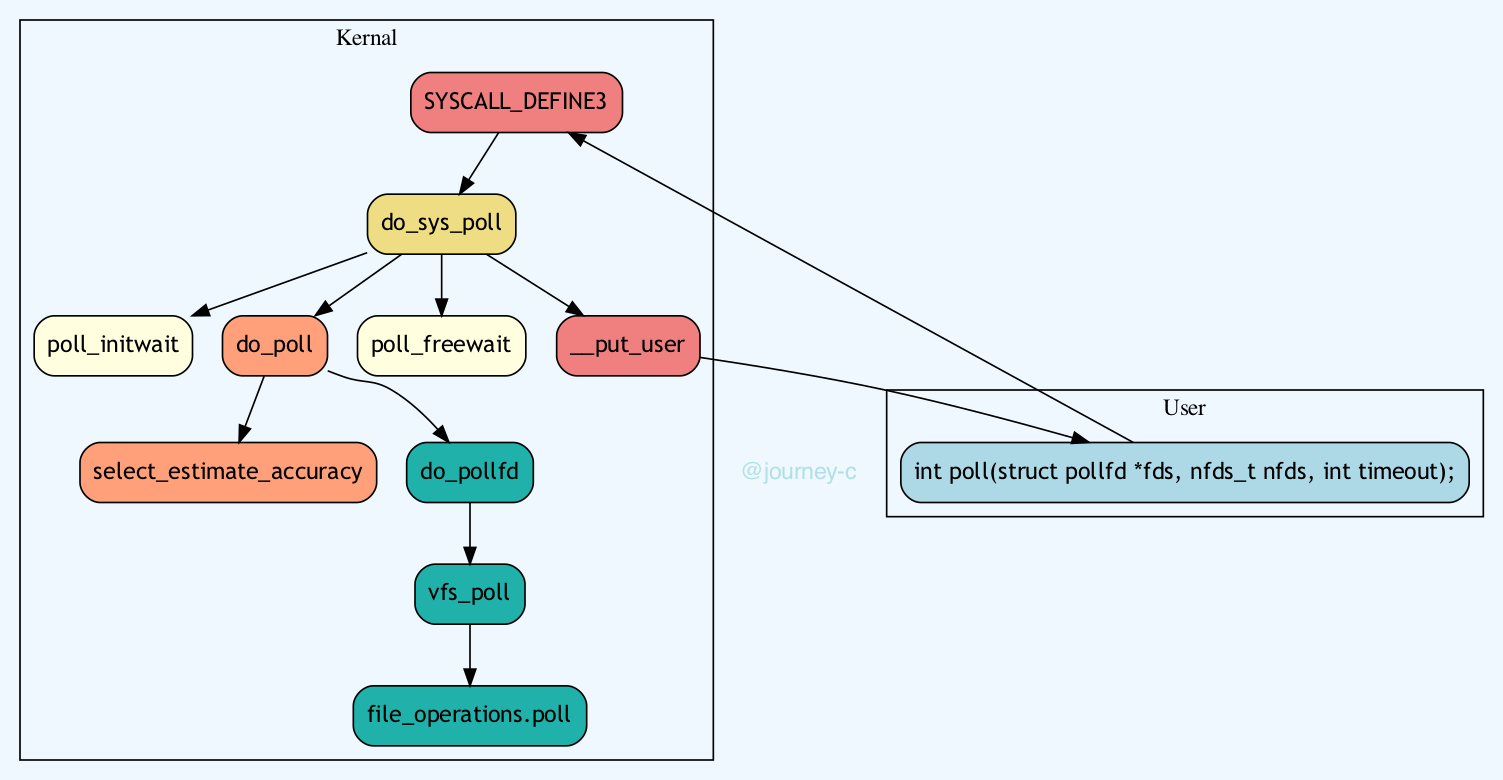
Poll和Select的入口都在fs/select.c中,下面我们来看一下Poll内核实现的流程:
- Poll的入口在SYSCALL_DEFINE3,SYSCALL_DEFINE3的主要工作是将timeout由相对时间转化为绝对时间。然后调用do_sys_poll
- do_sys_poll流程:
- 检查nfds是否超过进程最大可打开文件数,如果是就报错-EINVAL。
- 给输入参数分配空间再从用户空间拷贝过来,先试图在栈上分配,如果不够再从堆上分配。
- 调用poll_initwait初始化poll_wqueues(和select一样),然后调用do_poll,do_poll主要流程为:
- 调用select_estimate_accuracy设置过期时间。
- 然后就轮训所有的FD,调用do_pollfd检查FD的事件。do_pollfd也是调用vfs_poll来检测FD事件的,如果没有就将线程放入对应FD的等待队列等待被激活,自己休眠。(和select一样)
- 调用poll_freewait释放刚刚初始化的poll_wqueues。
- 调用
__put_user将结果拷贝回用户空间。 - 如果最开始参数是在堆上分配的,就释放内存。
4.3 小结
poll和select差不多,区别就是BitsMap换成了链表,FD数量只受poll可用内核内存大小限制。
- poll监听FD数量不再有限制(除线程本身限制外),但是每次调用poll还是要将FD集合拷贝到内核态,完成后再拷贝回来。
- 监听所有FD的方式还是轮训,$O(n)$的复杂度。
5. Epoll
5.1 使用
正因为select和poll有着各自的缺点,所以linux 2.5.44版本提供了新的I/O复用机制Epoll,在后续的版本中继续做了很多优化。
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
// 创建用于epoll工作的FD
int epoll_create(int size);
// 对事件操作:增、删等
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 等待事件
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
-
epoll_create
- size: 监听fd的数量,Linux 2.6.8就去掉了这个参数,因为要兼容,所以留着这个参数,但实际内核没用。
-
epoll_ctl
- epfd: epoll对应的FD
- op: 操作码,增(EPOLL_CTL_ADD),删(EPOLL_CTL_DEL),改(EPOLL_CTL_MOD)
- fd: 对epoll操作的源FD,例如要添加删除修改的FD
- event: 要监听的事件
-
epoll_wait
- epfd: epoll对应的FD
- events: 要等待的事件数组
- maxevents: 监听事件数量
- timeout: 超时时间,单位毫秒
5.2 实现
5.2.1 epoll_create
- epoll_create的入口在SYSCALL_DEFINE1,这个函数只是简单的检查了一下size是否为0,epoll_create的size参数随便填只要大于0即可,不使用的。然后调用了do_epoll_create对epoll_create操作统一处理。
- do_epoll_create流程如下:
- 检查一下flags除了EPOLL_CLOEXEC,还有没有其他的flag
- 调用ep_alloc申请一个eventpoll结构,这是存储epoll所有数据的数据结构。
- 调用get_unused_fd_flags根据flags申请一个本进程最小未使用的fd。
- 调用anon_inode_getfile创建一个对应匿名inode的file,file的私有数据存的是eventpoll结构体。inode在VFS中对应一个文件,记录了此文件在磁盘那些块以及文件各种信息,匿名inode就是将此文件的dentry(目录项)删掉了,在文件系统中一般是通过dentry(目录项)来查找使用文件,这样其他进程就用不了这个文件。相当于创建一个临时文件。
-
- 现在file(由进程打开的文件)有了,fd有了,把file和fd的关系放入本进程的open_files中,就相当于本进程打开了这个文件。
5.2.2 epoll_ctl
- epoll_ctl的入口在SYSCALL_DEFINE4,首先根据op选择要不要从用户空间拷贝参数(只要不是DEL都需要拷贝),之后就调用do_epoll_ctl做主要的工作了。
- do_epoll_ctl主要流程如下:
- 参数获取:
- 调用fdget根据epfd获得epoll对应的file(epoll_create时创建的),根据参数传入的fd获取对应的file。
- 参数 :
- 调用file_can_poll判断该文件支不支持poll函数,实际就是判断该文件对应的file_operation的poll函数为不为空。
- 判断系统支不支持autosleep功能,如果支持且用户也传入了EPOLLWAKEUP标志,就调用ep_take_care_of_epollwakeup将标志加到事件中,否则就将EPOLLWAKEUP事件丢弃。
- check一下要操作的fd是不是epfd(操作自己epoll的fd)和epfd是不是一个epoll fd。
- EPOLLEXCLUSIVE(since Linux 3.5)是一个FD被多个epoll监听时,当这个FD事件来临只有一个epoll会被唤起(避免惊群效应)。而epoll只允许add的时传入不允许mod时传入,这里就是check一下这种情况。
- 处理一种Epoll A包含Epoll B的FD,Epoll B也包含Epoll A的FD的情况,这时候如果其中一个FD有了事件,那么两个Epoll会循环被唤醒。
- 接下来就是核心操作:
- 根据file地址和fd大小 调用ep_find 查找传入fd是否在eventpoll结构体中的rbtree(存储所有监听的fd)已存在。rbtree的key就是epoll_filefd,比较规则,先比较file的地址,相同的话在比较fd的大小。
- 如果是ADD就调用ep_insert:
- 当前用用户的epoll_watch和max_user_watches检查是否还有可用空间,内核给每个用户的epoll可以用空间限制为syscall可使用空间的$1/25$。
- 从缓存中创建一个新的epitem(红黑树的value)。
- 初始化rdllink(满足事件链表),fllink(链接fd对应的file链表),pwqlist(poll等待队列)。
- 初始化epitem的参数,调用ep_set_ffd根据file,fd生成红黑树的key(struct epoll_filefd)等。
- 向插入fd对应file的epoll事件链表(f_ep_links)中新增事件。
- 将epitem插入红黑树。
- 调用init_poll_funcptr注册poll回调函数ep_ptable_queue_proc。在前select一节有描述。这里回调函数ep_ptable_queue_proc除了将task放入FD对应file的等待队列之外,事件来临还会调用ep_poll_callback函数。
- 调用ep_item_poll
- 如果不是epoll的FD就调用vfs_poll->file_operations.poll查询FD事件如果有就返回,没有就插入等待队列。
- 如果是epoll的FD,就调用ep_scan_ready_list将epoll的rdllist(已就绪的FD)传入用户空间。
- 如果有事件的话并且之前不在就绪链表rdllist,就放入就绪链表
- 如果是DEL就调用ep_remove:
- 调用ep_unregister_pollwait注销epoll_add时注册的file对应的poll_wait函数。
- 从各链表中删除。
- 从红黑树中删除。
- 如果是MOD就调用ep_modify:
- 修改FD事件。
- 调用ep_item_poll查询是否修改后有事件,有的话就放入rdllist就绪链表。
- 参数获取:
5.2.3 epoll_wait
- epoll_wait入口在SYSCALL_DEFINE4,之后调用do_epoll_wait
- do_epoll_wait主要流程:
- 检查参数,参数是否正确,返回结果地址是否正确,要操作的epollfd是否正确。
- 调用ep_poll
- 如果有timeout不为零,就将时间转化为绝对时间,如果为0就检查一下当前就绪队列是否为空,如果有事件直接返回,没有事件就返回空。
- 调用ep_events_available检查当前有无就绪FD,有就直接返回,或者当前file_operations->poll函数正忙就等等,看工作完有没有。
- 如果没有就进入死循环,和select一样,将task设为TASK_INTERRUPTIBLE,等待被唤醒或被信号唤醒或超时。
- 直到被唤醒依然调用ep_events_available检查有没有就绪FD,有的话就调用ep_send_events将结果传回用户空间。
- ep_send_events调用ep_scan_ready_list扫描rdllist链表并且调用ep_send_events_proc将事件发回用户空间,如果FD的使用的epoll的模式为EPOLLET(水平触发)发送完之后重新被加入rdllist链表,等待下次epoll_wait时,如果fd在rdllink中且已经不可读了就不再加入rdllist中了。
- 发送会用户空间之后,将因为rdllist发送时加锁而没加入的事件(放入了ovflist)加入rdllist。
5.3 小结
select和poll的模式都是,一次将参数拷贝到内核空间,等有结果了再一次拷贝出去,类似无状态服务。而epoll则只是在epoll_ctl(ADD)时将数据拷入,epoll_wait时在将数据拷出,多次复用没有其他数据拷贝,大大节省了数据拷贝。epoll采用红黑树存储所有被监听的FD是的查找删除时间复杂度由$O(N)$缩短为$O(log^N)$。
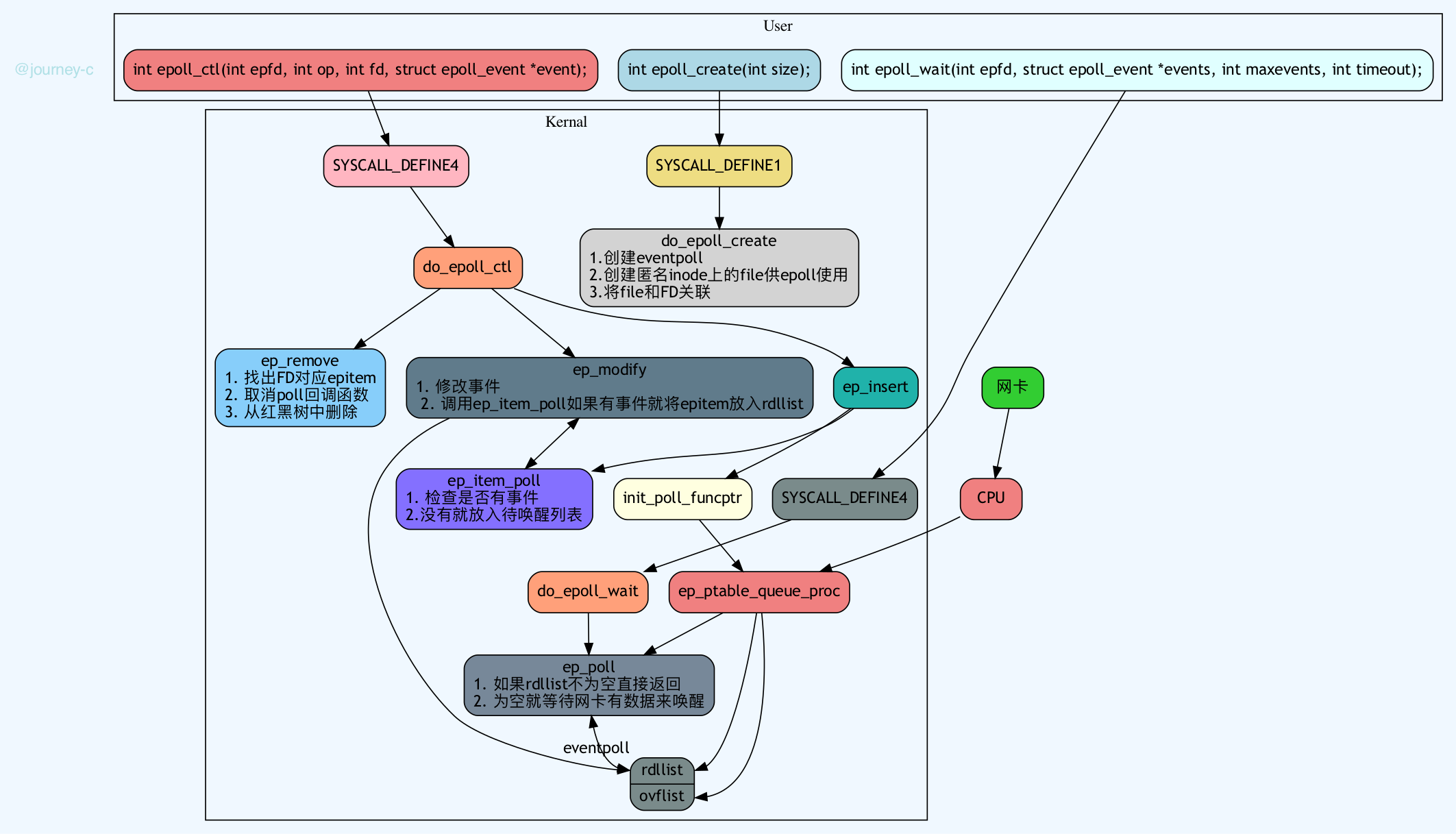
- epoll_create创建eventpoll结构。
- epoll_ctl:
-
- ADD检查FD事件,有就加入rdllist队列,没有就将task放入FD对应file的待唤醒列表,将FD加入红黑树维护。
-
- DEL从eventpoll的各个资源中删除。
-
- MOD修改事件,并再次检查FD事件,有就加入rdllist队列,没有就将task放入FD对应file的待唤醒列表并且注册事件回调函数——有事件来临就加入rdllist。
-
- epoll_wait检查rdllist有没有已经就绪的FD,没有就等待时间来临唤醒,有事件就返回用户空间,并且清空rdllist链表,如果FD是EPOLLLET模式的就重新加入rdllist链表中,等待下次epoll_wait看情况清理。
6. select、poll、epoll对比
| 名称 | 监听FD数量 | 数据拷贝 | 操作复杂度 |
|---|---|---|---|
| select | 1024 | 每次操作从用户空间拷入内核空间然后拷出 | $O(N)$ |
| poll | 内核限制sys内存大小 | 每次操作从用户空间拷入内核空间然后拷出 | $O(N)$ |
| epoll | 内核限制sys内存大小 | ADD时拷贝一次,epoll_wait时利用MMAP和用户共享空间,直接拷贝数据到用户控件 | $O(1)$ |
7. 事件回调
select/poll/epoll最后都会调用vfs_poll,检查FD是否有相应事件。 vfs_poll的核心流程就是:
- 先检查FD对应的file目前是否已有事件,如果没有则将当前task(linux中线程进程都是task)加入到file的wait_queue,然后就让出CPU,等待被激活。
- 当file对应的设备有事件来临时,会激活file的wait_queue中所有等待的task(将task从等待态变为运行态,重新加入到调度列表中)。
CPU1 CPU2
sys_select receive packet
... ...
__add_wait_queue update tp->rcv_nxt
... ...
tp->rcv_nxt check sock_def_readable
... {
schedule rcu_read_lock();
wq = rcu_dereference(sk->sk_wq);
if (wq && waitqueue_active(&wq->wait))
wake_up_interruptible(&wq->wait)
...
}
7.1 流程
下面我们以socket为例,分析一下事件是如何回调的。
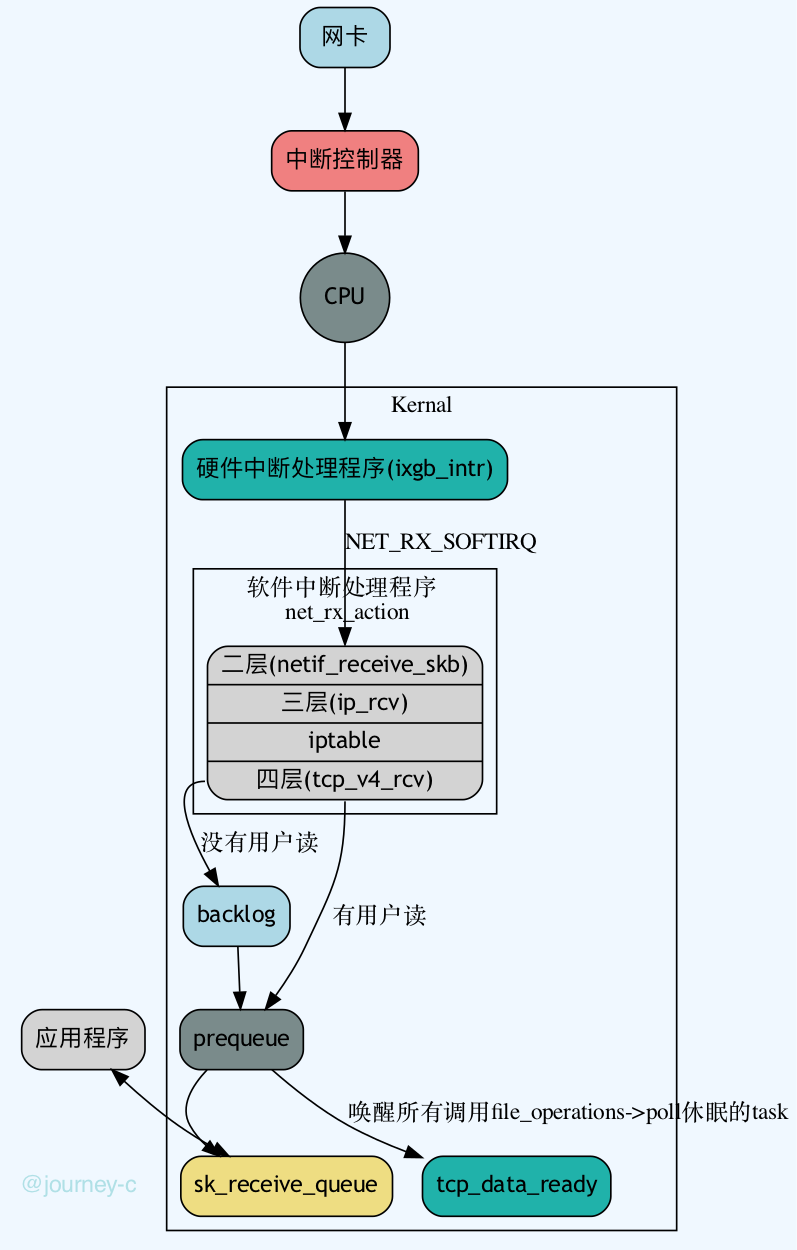
设备驱动层主要做的事情是,网卡作为一个硬件,当收到网络包的时候如何通知操作系统。没错,是硬件中断,硬件和操作系统打交道的方式基本都是硬件中断。而网卡与内核交互采用了硬件中断+下半部(主要是拷贝数据太耗时,放在中断处理程序中不妥)
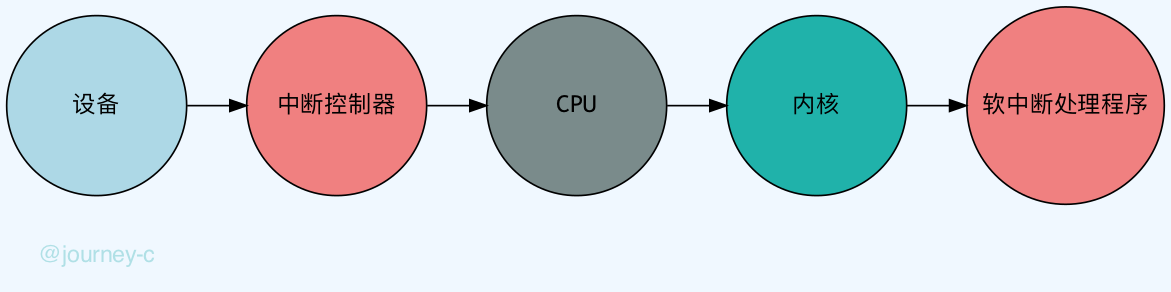
- 设备给中断控制器引脚发送信号。
- 中断控制器收到后给CPU发送信号。
- CPU收到信号后产生中断,根据中断号在中断向量表中执行内核实现的中断处理程序。(执行程序实际就是已经与内核通讯了)
以intel的ixgb网卡为例。
- 网卡程序初始化时调用ixgb_init_module注册驱动ixgb_driver,并且调用驱动的probe函数ixgb_probe。
- ixgb_probe中与本文相关的有:
-
- 创建一个struct net_device表示网络设备。
-
- 设置网卡的相关操作ixgb_netdev_ops,其中ndo_open函数是网卡激活时执行的函数,对应ixgb网卡的ixgb_open函数。调用netif_napi_add为这个网络设备注册一个轮询 poll 函数 ixgb_clean,将来一旦出现网络包的时候,就是要通过它来轮询了。
-
- 当网卡有数据来临时,网卡给中断控制器发送信号,中断控制器给CPU发送信号,CPU执行对应的中断处理函数ixgb_intr
-
- ixgb_intr中调用__napi_schedule和___napi_schedule将设备标记,触发软件中断NET_RX_SOFTIRQ,软件中断号对应的中断处理函数为net_rx_action
-
- net_rx_action调用napi_poll轮询所有的网络设备,napi_poll调用网卡注册是注册的poll函数ixgb_clean
-
- ixgb_clean调用ixgb_clean_rx_irq读取数据并将数据存放到struct sk_buff中,然后调用netif_receive_skb处理二层的数据。
-
- 从netif_receive_skb开始处理二层的数据,调用链netif_receive_skb_internal->__netif_receive_skb->__netif_receive_skb_core
-
- __netif_receive_skb_core中根据协议头将数据交给三层对应的协议栈。
-
- 现在就开始处理三层的数据里,假如当前的包是一个IPv4的包,数据就会流向ip_rcv
-
- ip_rcv中得到IP的报头,然后调用NF_HOOK判断路由,不是本机的包就发走,是本机的包就调用ip_rcv_finish
-
- ip_rcv_finish调用ip_rcv_finish_core然后根据IP报头中的协议把数据交给四层的协议栈。
-
- 千辛万苦数据终于来到了四层,假如当前是一个TCP包的话。会调用tcp_v4_rcv
-
- tcp_v4_rcv根据IP以及tcp报头内容在tcp_hashinfo (inet_hashinfo)找到对应socket
-
- 接下来根据socket的不同状态进行处理,socket根据情况进入三个不同队列,这一步主要是先将包找个地方放一下,赶紧离开中断状态。
-
- backlog 当前没有用户在读数据,就将socket 放入backlog中,离开软件中断状态(到之前为止一直在软件中断中)
-
- prequeue 如果当前有用户在读数据,且一个窗口的包还没收集完就放入prequeue
-
- sk_receive_queue 当一个窗口的包准确收集完了,就放入sk_receive_queue中,用户可读取了。
-
- 当一个窗口的包准确收集完之后,就会调用tcp_data_queue将数据放入sk_receive_queue,然后调用tcp_data_ready,在调用sock的sk_data_ready函数sock_def_readable,sock_def_readable会唤醒之前因为调用file_operations.poll为阻塞的进程或线程。
-
- 这就到了咱们最关心的问题了,tcp_data_ready唤醒的是哪些task。
7.2 流程图